For this week in machine learning, I am sharing two interesting tutorials from VLDB and KDD conferences this week.
Managing ML Pipelines: Feature Stores and the Coming Wave of Embedding Ecosystems [slides][paper]
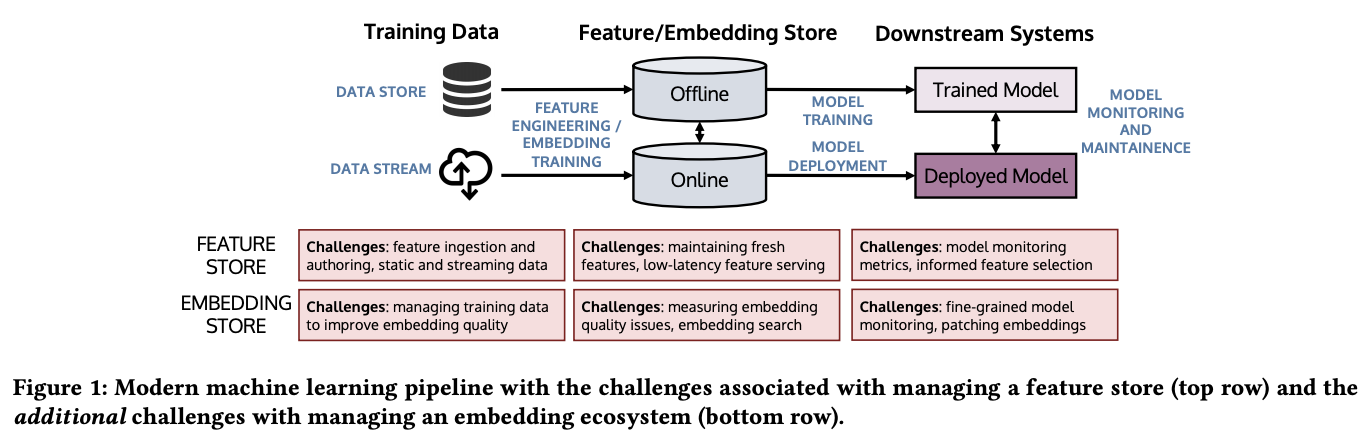
Machine learning pipeline is an iterative process involving data curation, feature engineering, training and deploying models, as well as monitoring and maintenance of the deployed models. In large system with many downstream tasks, a feature store is important to standardize and manage feature generation and workflows in using the features. With the advent of self-supervised pre-trained embedding models as features, feature store faces new challenges to manage embeddings.
This VLDB 2021 tutorial gives an overview of the machine learning pipeline and feature store. Then, it introduces embeddings and the challenges faced by feature store in dealing with embeddings. Finally, it introduces recent solutions to some of the challenges and discussion on the future direction.
Modern machine learning pipeline with feature / embedding store. Figure taken from (Orr et al., 2021).
All You Need to Know to Build a Product Knowledge Graph [website]
This tutorial by Amazonian at KDD 2021 presents best practices in building scalable product knowledge graph. Building product knowledge graph is more challenging than generic knowledge graph due to the sparsity of the data, the complexity of the product domains, evolving taxonomies, and noise in the data.
The tutorial covers the solutions to answer the challenges in building product knowledge graph including knowledge extraction, knowledge cleaning, and ontology construction. Finally, it concludes with some practical tips and future directions.
That’s all for this week. Stay safe, and see you next week.
Geometric Deep Learning (DGL) course publishes great course materials including slides and video recording on the topic of Geometric Foundations of Deep Learning (which I shared some time ago). The course was delivered as part of African Master’s in Machine Intelligence (AMMI 2021). I will take time to go through all the lecture videos of this course.
BERTopic is a topic modeling technique that performs a density-based clustering on document representation (encoded using a transformer-based model). BERTopic utilizes class-based TF-IDF (c-TF-IDF) to get important words on each topic.
This library provides easy-to-use API to perform BERTopic, and visualize topics. In addition, it also supports various pre-trained models such as Sentence Transformer, Flair (allows you to use Huggingface pre-trained transformer models), Spacy, Gensim, and Universal Sentence Encoder (USE).
How to avoid machine learning pitfalls: a guide for academic researchers [paper]
This paper discusses common mistakes when using machine learning techniques, and how to avoid them. The paper is very suitable to anyone new in machine learning area. It covers pitfalls in every stage of machine learning development including data preparation, model development, evaluation to reporting. Here is the outline of the paper.
The content of the paper.
That’s all for this week. Stay safe and see you next week.
This week, I read a paper on pre-processing training data for Language models. Here is a short summary.
Deduplicating Training Data Makes Language Models Better [paper][github]
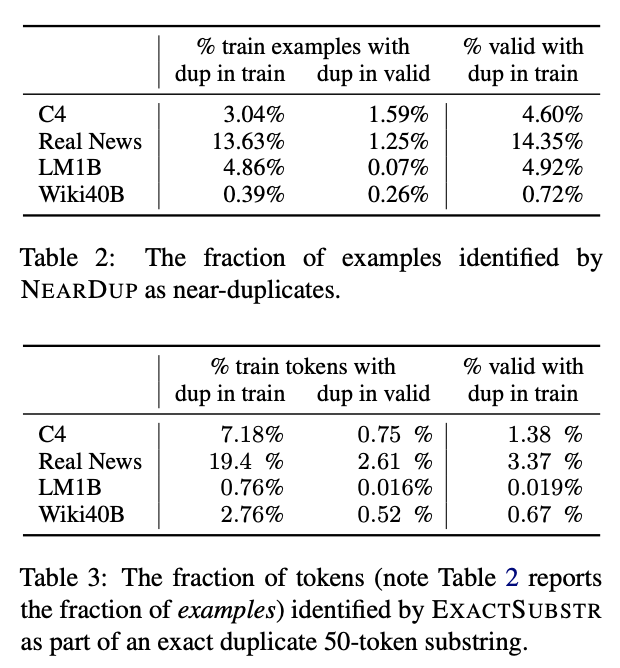
This paper shows that datasets for language modeling contain many long repetitive substrings and near-duplicate examples, for example a single 61-word sentence repeated over 60,000 times in C4 dataset. To address this issue, the authors of this paper propose two scalable deduplication methods to detect and remove duplicate sequences.
The advantages of training a language model on deduplicated datasets are as follow:
Reducing the rate of emitting memorized training data.
Removing train-test overlap that is common in non-deduplicated datasets. Train-test overlap causes model overfitting.
More efficient model training due to smaller datasets.
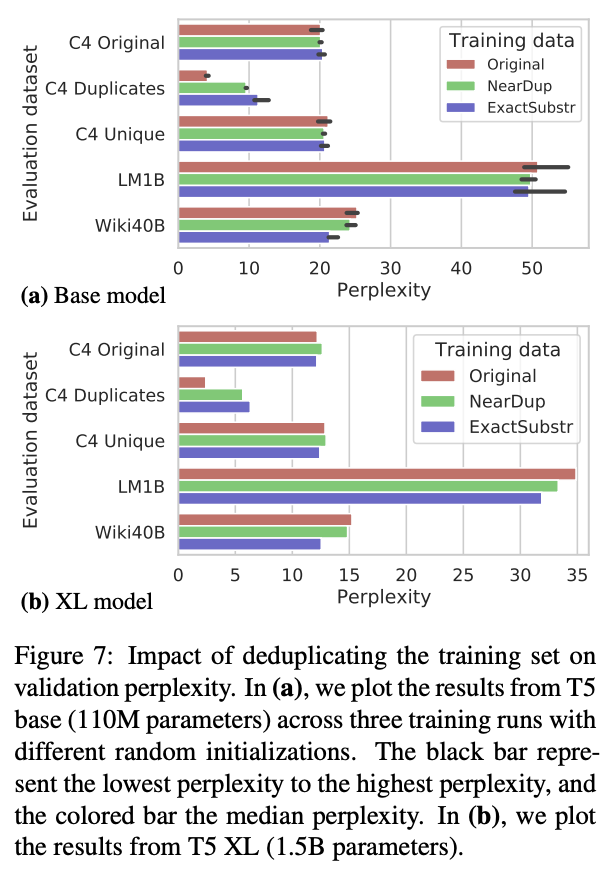
Deduplicating training data does not hurt perplexity.
Naive method to perform deduplication using exact string matching on all example pairs is not scalable. Two deduplication methods are introduced in this paper:
Removing exact substring duplication using suffix array (ExactSubstr)
Approximate matching with MinHash (NearDup)
More details on each method can be read in the paper. The authors also release the source codes.
Below are the percentage of duplicate examples in standard LM datasets detected by ExactSubstr and NearDup methods, as well as the impact of deduplicating training set on validation perplexity.
Percentage of duplicate example in datasets detected by ExactSubstr and NearDup. Table taken from (Lee et al., 2021).Impact of deduplicating training set on validation perplexity. Figure taken from (Lee et al., 2021).
For this week in machine learning, we look into biases in AI system from CACM (Communication of ACM) article for August 2021. The article nicely explains overview of biases that can present in our AI systems. Here are my short note.
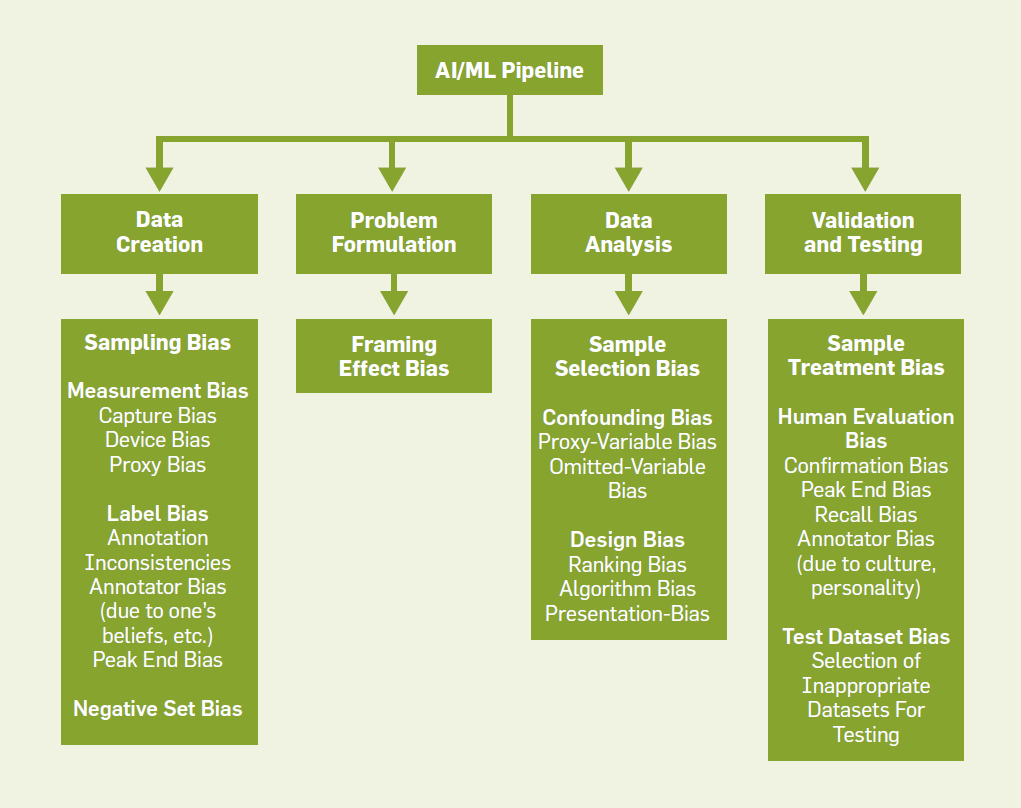
Machine learning is a complex system, and it involves learning from a large dataset with a predefined objective function. It is well-known too that Machine learning systems exhibit biases that comes from every part of the machine learning pipeline: from dataset development to problem formulation to algorithm development to evaluation stage.
Detecting, measuring, and mitigating biases in machine learning system, and furthermore, developing fair AI algorithm are not easy and still active research areas. This article provides a taxonomy of biases in the machine learning pipeline.
Machine learning pipeline begins with dataset creation, and this process includes data collection, and data annotation. During this process, we may encounter 4 types of biases:
Sampling bias: caused by selecting particular types of instances more than others.
Measurement bias: caused by errors in human measurement or due to certain intrinsic habits of people in capturing data.
Label bias: associated with inconsistencies in the labeling process.
Negative set bias: caused by not having enough negative samples.
Next stage is problem formulation. In this stage, biases are cause by how a problem is defined. For example, in creditworthiness prediction using AI, the problem can be formulated based on various business reasons (such as maximize profit margin) other than fairness and discrimination.
On algorithm and data analysis, several types of biases that potentially can occur in your system:
Sample selection bias: caused by selection of data instances as a result of conditioning on some variables in the dataset
Confounding bias: it happens because the machine learning algorithm does not take into account all the information in the data. Two types of confounding bias:
omitted variable bias
proxy variable bias, for example zip code might be indicative of race
Design bias: caused by the limitation of the algorithm or other constraints on the system. It could be in the form of algorithm bias, ranking bias, or presentation bias.
Here are several types of biases on the evaluation and validation stage:
Human evaluation bias: caused by human evaluator in validating the machine learning performance.
Sample treatment bias: selected test set for machine learning evaluation may be biased.
Validation and test dataset bias: due to selection of inappropriate dataset for testing.
Beside the taxonomy of bias types, the authors also give some practical guidelines for machine learning developer:
Domain-specific knowledge is crucial in defining and detecting bias.
It is important to understand features that are sensitive to the application.
Datasets used for analysis should be representative of the true population under consideration, as much as possible.
Have an appropriate standard for data annotation to get consistent labels.
Identify all features that may be associated with the target feature is important. Features that are associated with both input and output can lead to biased estimates.
Restricting to some subset of the dataset can lead to unwanted sample selection bias.
Avoid sample treatment bias when evaluating machine learning performance.
I share few interesting open source projects related to machine learning deployment, neural search framework, and flexible machine learning data structure for this week in machine learning.
Parallelformers: An Efficient Model Parallelization Toolkit for Deployment [github][documentation]
Parallelformers helps us to deploy most big transformer-based model on multiple gpus for inference. It is designed to make model parallelization easier, and we can parallelize many Huggingface transformer models with a single line of code.
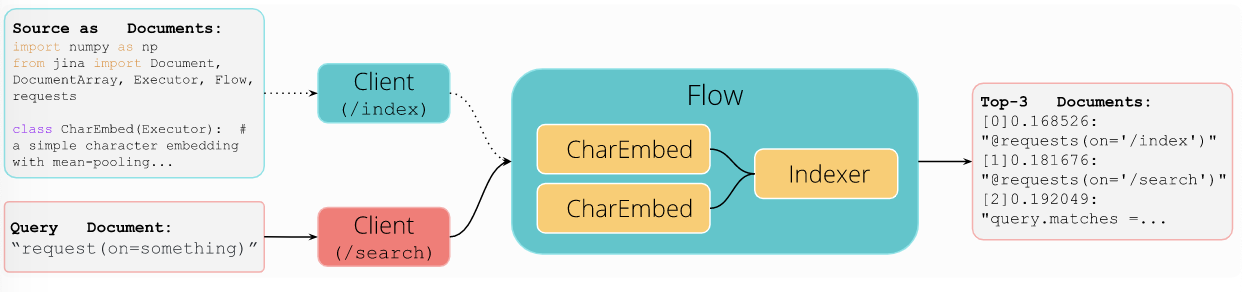
Jina: Cloud-native neural search framework for any kind of Data [github]
Building a search engine is hard, especially when our data are not text data. Neural search leverages on state-of-the art deep neural network to perform information retrieval, and it enables retrieval of any kinds of structured data such as images, video, audio, 3D mesh, etc. Jina is a neural search framework allowing us to build neural search engine as a service quickly. It employs distributed architecture, and cloud-native by design. Take a look at its quick demo.
Meerkat: Flexible data structure for complex machine learning datasets [github][blog]
With various type of machine learning data (such as images, graphs, videos, time-series), a simple data abstraction for data wrangling greatly helps ML practitioners to interact with high-dimensional, and multi-modal data. Inspired by Panda DataFrame and combined with the capability of from recent data abstraction in deep learning framework such as PyTorch Dataset and Tensorflow Dataset), Meerkat DataPanel provides a simple data abstraction that offers best of the both world. Meerkat DataPanel supports:
Datasets that are larger-than-RAM with efficient I/O under-the-hood
Multi-modal datasets
Data creation and manipulation
Data selection
Inspection in interactive environment
Note that PyTorch Dataset and Tensorflow Dataset support number 1-3 in above list, whereas Panda DataFrame supports number 4-6 in above list. Read their blog for more detail examples on how Meerkat DataPanel helps us wrangle our datasets.
Following my study on unsupervised domain adaptation last week, I write a short note on domain divergences survey for this week in machine learning. In domain adaptation, domain divergence measures the distance between the two domains, and reducing the divergence is important to adapt machine learning models to a new target domain.
A Survey and Empirical Analysis on Domain Divergences [paper]
As a measure of the distance between two domains, domain divergence is a major predictor of performance in target domain. Domain divergence measures can be utilized to predict performance drop when a model is applied in a target domain. This paper reviews 12 domain divergence measures, and reports a correlation analysis study on those divergence measures on part-of-speech tagging, named entity recognition, and sentiment analysis on more than 130 domain adaptation scenarios.
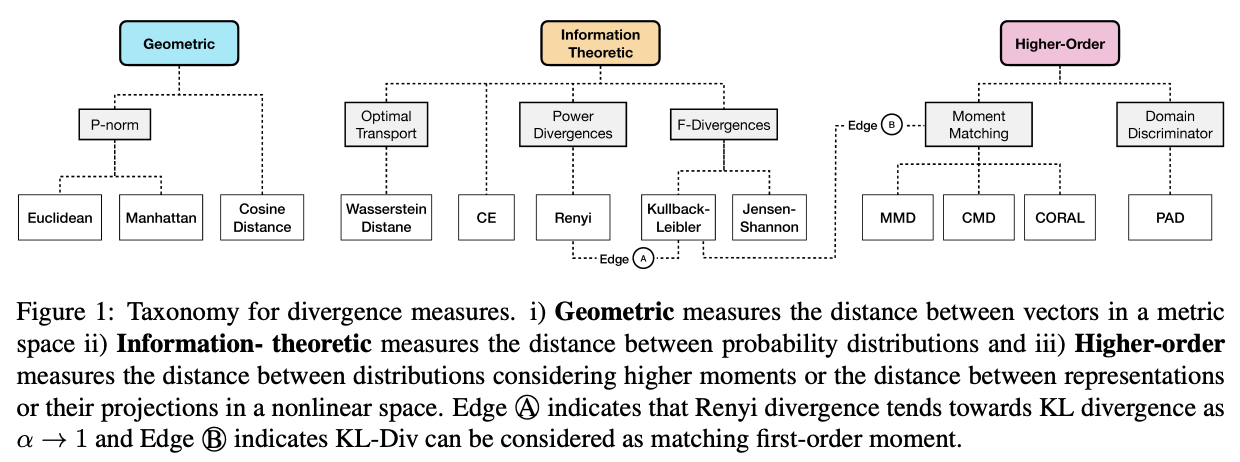
Domain divergence can be categorized into three categories:
Geometric measures Geometric measures use vector space distance metric such as Cosine similarity, Manhattan, and Eucledian distance to measure the distance between features extracted from instances from different domains . These measures are easy to compute, but do not work well in a high dimensional space.
Information theoretic Information theoretic measures capture the distance between probability distributions, for example cross entropy, f-divergences (KL and JS divergence), Renyi divergence, and Wasserstein distance.
Higher-order measures Higher-order measures consider higher order moment matching of random variables or divergence in a projected space. Maximum Mean Discrepancy (MMD), CMD, and CORAL are measures utilizing higher order moment matching, whereas Proxy-a-distance (PAD) uses a classifier to measure the distance between source and target domain.
Note that KL divergence is related to both Renyi divergence and first-order moment matching.
How do we apply divergence measures?
According to this survey paper, the divergence measures can be applied in three different ways:
Data selection One way is to use divergence measures to select a subset of data from source domain that share similar characteristics to the target domain. For example, using cosine similarity or JS divergence to select data for POS tagging.
Learning representation Another way is to learn a new representations that are invariant to the data sources. Domain Adversarial Neural Network (DANN) uses a domain classifier as a proxy-a-distance (PAD) to measure the distance between source and target domain. A good domain-invariant representation should be able to confuse the domain classifier whether it comes from source or target domain. Another example is to use MMD to reduce the discrepancy between representations belonging to the two domains.
Decision in the wild Predicting performance drops on target domain where no labelled data are available is an important practical problem. Some previous work uses information theoretic measures like cross entropy, Renyi and KL divergence to predict performance drops in a new domain.
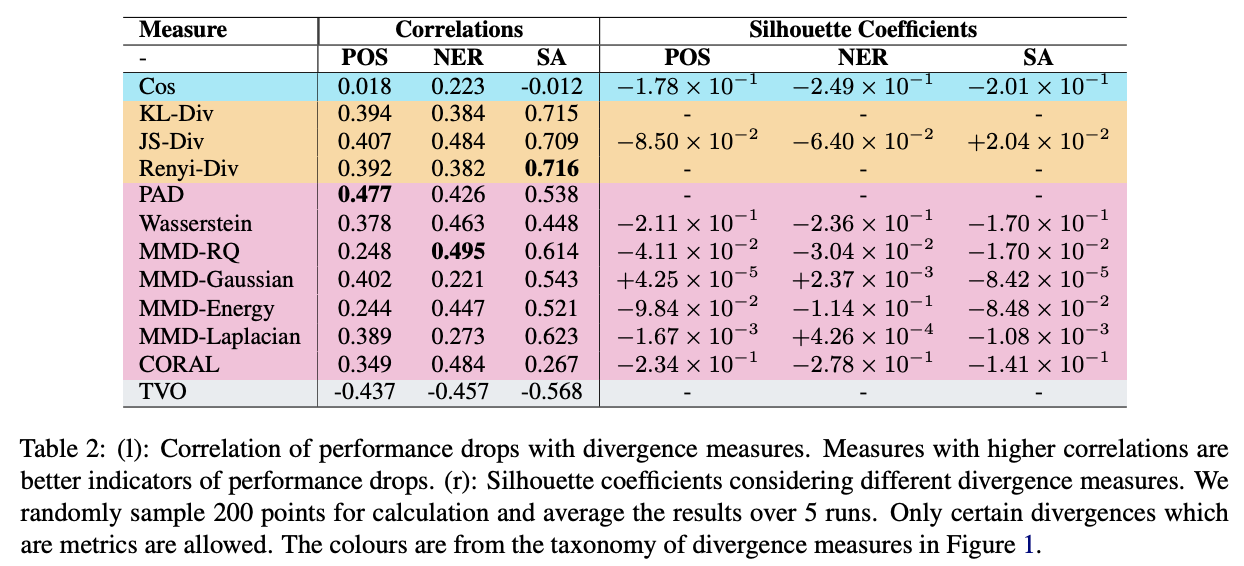
Correlation of performance drops with divergence measures. PAD is the most reliable measures to indicate performance drops on target domain. Table taken from (Kashyap et al., 2021).
The authors also run an experiment to see the correlation between divergence measures and performance drops in target domain. More detail experiment setting and discussion can be read in the paper. Here are some recommendation from the authors based on their experiments:
PAD is a reliable indicator of performance drop.
JS divergence is easy to compute, and can be a strong baseline.
Cosine similarity is not a reliable indicator of performance drop.
One dataset is not one domain, but a cluster representations of multiple domains.
That’s all for today. Stay safe and see you next week!
For machine learning week, I study about unsupervised domain adaptation in NLP this week, reading a relevant survey paper in this area. Here are my short summary notes.
A Survey on Neural Unsupervised Domain Adaptation in NLP [paper][github]
In many NLP applications, the availability of the labeled data is very limited. Although deep neural network works well for supervised learning, particularly with pre-trained language model to achieve state-of-the-art performance on NLP tasks, there is still a challenge to learn from unlabeled data under domain shift. In this setting, we have two problems to tackle:
The target domain and the source domain do not follow the same underlying distribution (Note that the task is the same). For example,
The source domain is news and wikipedia articles, and the target domain is scientific literatures.
The more extreme case is cross-lingual adaptation, the source domain is in one language, and the target domain is in another language.
The scarcity of labeled data in the target domain, and we need unsupervised domain adaptation techniques to handle this issue.
This survey summarizes relevant work on unsupervised domain adaptation where we mitigate the domain shift by learning only from unlabeled target data. The authors also discuss the notion of domain (what constitute a domain?), and suggest to use better term: variety space.
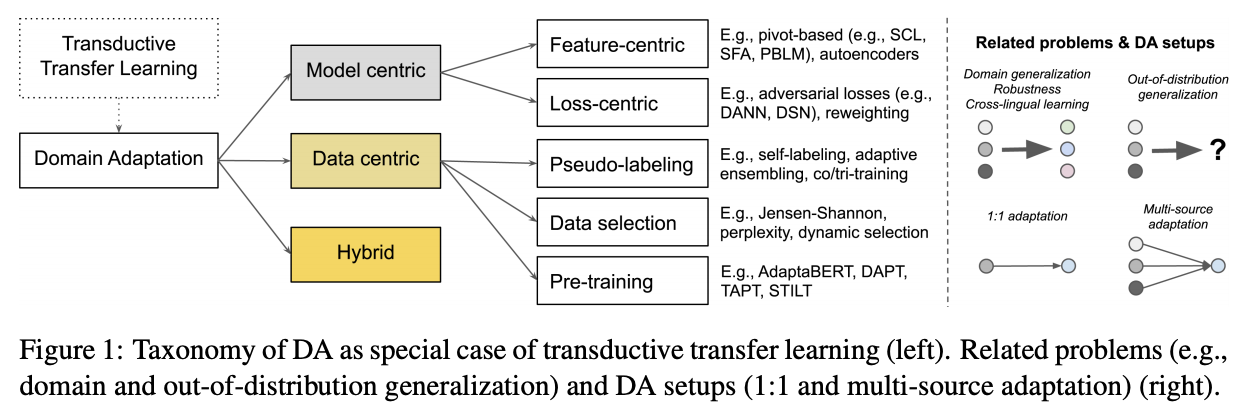
Domain adaptation methods can be categorized into 3 groups of approaches:
Model-centric approaches: redesign parts of the model by modifying feature space or loss function.
Feature-centric methods by feature augmentation or feature generalization.
Feature augmentation methods uses common shared features (called pivots) to construct aligned space, for example structural correspondence learning (SCL), spectral feature alignment (SFA), and pivot-based language model (PBLM).
Feature generalization utilizes autoencoder to find good latent representation that can be transferred across domains. Stacked denoising autoencoder (SDA), marginalized stacked denoising autoencoder (MSDA) have been used for unsupervised domain adaptation.
Loss-centric methods to regularize or modify model parameters. It can be divided into two groups: domain adversaries and instance-level reweighting.
Domain adversaries is probably the most popular methods for neural unsupervised domain adaptation. The idea is inspired by GAN approach which tries to minimize real and synthetic data distribution by learning a representation that cannot be distinguish between real and synthetic data. Bringing that into the domain adaptation setting, cross-domain representation can be achieved, if a domain classifier cannot distinguish whether the input comes from the source or the target domain. A popular Domain adversarial neural network (DANN) uses a gradient reveral layer to achieve cross-domain representation. A more recent approach utilizes Wassertein distance to achieve cross-domain representation.
The idea of instance-level reweighting methods is to assign a weight on each training instance proportional to its similarity to the target domain.
Other methods explicity reweight the loss based on domain discrepancy information, such as maximum mean discrepancy (MMD), and kernel mean matching (KMM).
Data-centric approaches: focuses on getting signal from the data.
Pseudo-labeling using a trained labels to bootstrap initial ‘pseudo’ gold labels on the unlabeled instances. Pseudo-labeling applies semi-supervised methods such as self-training, co-training, and tri-training.
Data selection aims to find the best matching data for the new domain using domain similarity measures such as JS divergence or topic distribution.
Pre-training models leveraging large unlabeled data. Starting from a pre-trained transformer model followed by fine-tuning on small amount of labeled data has become the standard practice in NLP due to high performance on many NLP tasks. In domain adaptation, pre-training can be divided into:
Pre-training alone
Adaptive pre-training involving multiple rounds of pre-training
Multi-phase pre-training: pre-training followed by two or more phases of secondary pre-training, from broad domain to specific domain to task-specific domain, for example: BioBERT, AdaptaBERT, DAPT, TAPT.
Auxiliary-task pre-training: pre-training followed by multiple stages of auxiliary task pre-training involving intermediate labeled-data tasks.
Hybrid approaches: intersection between model-centric and data-centric.
One of the authors, Barbara Plank, created a Github repo to collate all relevant papers in this area.
Hello, I am sharing einops library, an MLOps course, and ACM Turing Lecture on deep learning for AI for this week in machine learning.
Writing better deep learning codes with einops [github][website]
Einops (Einstein-inspired Notation for Operations) is a simple, flexible, and powerful tensor operation library for more readable codes. This library supports many backend such as numpy, pytorch, tensorflow, jax, gluon, tf.keras, cupy, chainer, and mxnet.
Using this library, we can focus on the input and output interface of tensor operations, rather than how it is computed, making our code more readable and easier to maintain. It also reduces the chance of making unnecessary errors in our code. Watch the short video below, and pytorch with einops comparison to get a better sense of how to make our code more readable with this library.
Goku Mohandas created a project-based course on how to apply ML to build production grade product. The course walks through product development and iteration cycle. It covers product planning, data transformation, modeling, reproducibility, scripting, testing, and production. More details on lesson highlight can be seen in Goku’s tweet thread.
MLOps Course by Goku Mohandas.
ACM Turing Lecture: Deep Learning for AI [article]
In this article, Bengio, LeCun, and Hinton review the rise of deep learning in AI, describe recent advances in deep learning, and discuss the future directions of deep learning in AI. The rise of deep learning attributed by deep architecture, unsupervised pre-training, success of Rectified Linear units (ReLUs). Deep learning also leads some breakthrough in speech and object recognitions. Several recent advances in deep learning are briefly mentioned in this article: Attention and transformer architecture, unsupervised and self-supervised learning, contrastive learning, and variational auto-encoder.
The discussion on future of deep learning suggests several improvement based on some current AI limitation compare to human learning such as: ability to generalize faster without too many trials, and adaptability and robustnes to changes in distribution (out-of-distribution generalization). In addition to this, applying deep learning on tasks which require a deliberate sequence of steps also another exciting future direction.
This week in machine learning features NAACL 2021 Best short paper which is also related to PET we discuss last week. Let see main ideas for this paper.
How Many Data Points is a Prompt Worth? [paper][blog][github]
The standard approach for transfer learning using pretrained model for classification is to attach a head layer to perform classification, taking in the pretrained representation to predict the output class. The other alternative approach is to use a prompt, reformulating the task into a task-specific string and ask the model to produce a textual output corresponding to a class label. Prompt-based approach provides a more flexible way to inject extra task-specific guidance to fine tune the model. PET (which we discuss last week) has shown that prompt-based effectiveness on low-data regimes.
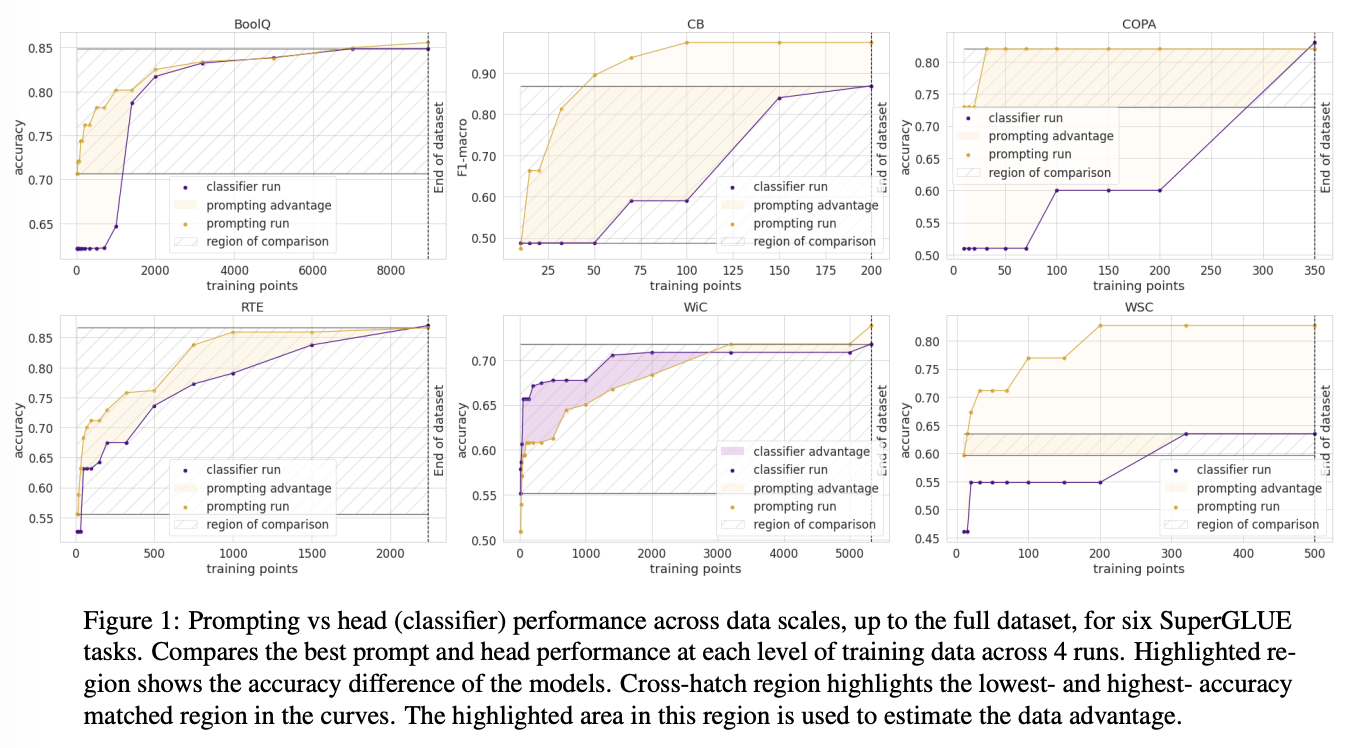
This NAACL 2021 best short paper presents a very nice analysis comparing head-based and prompt-based, aiming to quantify how many data points is a prompt worth? The author takes a roberta-large and compare the performance using head-based and prompt-based approach across different available data points (starting from 10 data points and increasing exponentially). For the prompt-based approach, they follow PET model (Schick and Schütze, 2021).
Using the both head-based and prompt-based performance curves on all data points, the data point advantage is estimated by first isolate the y-axis band of the lowest accuracy and the highest accuracy where two curves match in accuracy (this is shown in cross-hatch region in the figure below). Then, the area between two linearly-interpolated curve divided by the height of the band represents the number of data point advantage.
Prompting versus Head classifier performance on SuperGLUE. Highlighted area in cross-hatch region shows the data advatage. Figure taken from (Scao and Rush, 2021).
Experiment results on SuperGLUE benchmark shows prompt-based data advantage on all tasks except WiC. Notable data advantage can be seen in low-data regime.
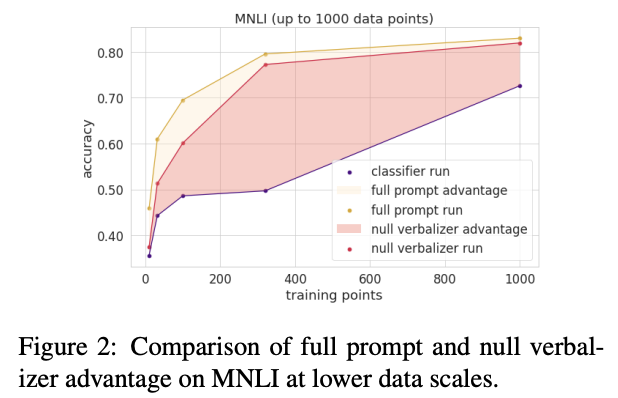
The authors also perform analysis on the impact of verbalizer in prompt-based approach. To do this, they introduce null verbalizer (random first name to replace “yes”, “no”, “maybe”, “right”, “wrong”). They find that verbalizer is important especially when the availability of the training data points is low. Null verbalizer reduces the prompt-based performance in low-data regime. However, with more and more training data, prompt-based model can adapt to null verbalizer.
Comparison of full prompt and null verbalizer. Figure taken from (Scao and Rush, 2021).
That’s all for this week. Stay safe and See you next week!
We have NAACL 2021 best paper, a great survey paper of Transformer models, a free NLP course, and an open source NLP library for Machine learning this week. Let’s take a look at them.
It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners [paper][blog]
GPT-3 model has shown its superior few-shot performance in many NLP tasks. However, GPT-3 is a gigantic model, and training GPT-3 needs huge computing power that is not practical for many people. This NAACL 2021 best paper proposes an effective alternative method to train a few-shot learner models using small language model. The main idea is reformulating tasks as cloze questions, and providing a gradient-based learning with few of these cloze questions training examples.
Reformulation sentiment classification as a cloze question. Figure taken from Schick’s blog.
The algorithm is called Pattern-exploiting training (PET). This algorithm needs two components:
Pattern: a conversion of input into a cloze question
Verbalizer: an expression of the output using one or more words.
In the figure shown above, we convert sentence “Excellent pizza!” into “Excellent pizza! It was ____”. Then, we ask the model to verbalize “good” for positive sentiment, or “bad” for negative sentiment.
This paper also shows an extensive experiment to identify factors contributing to strong PET performance such as the choice of patterns, and verbalizers, the usage of both unlabeled and labeled data, and properties of the underlying language model.
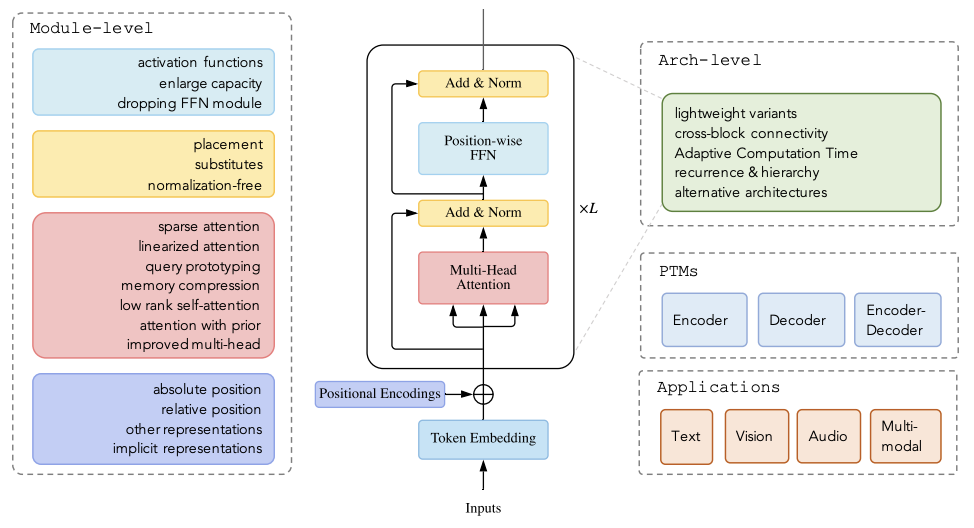
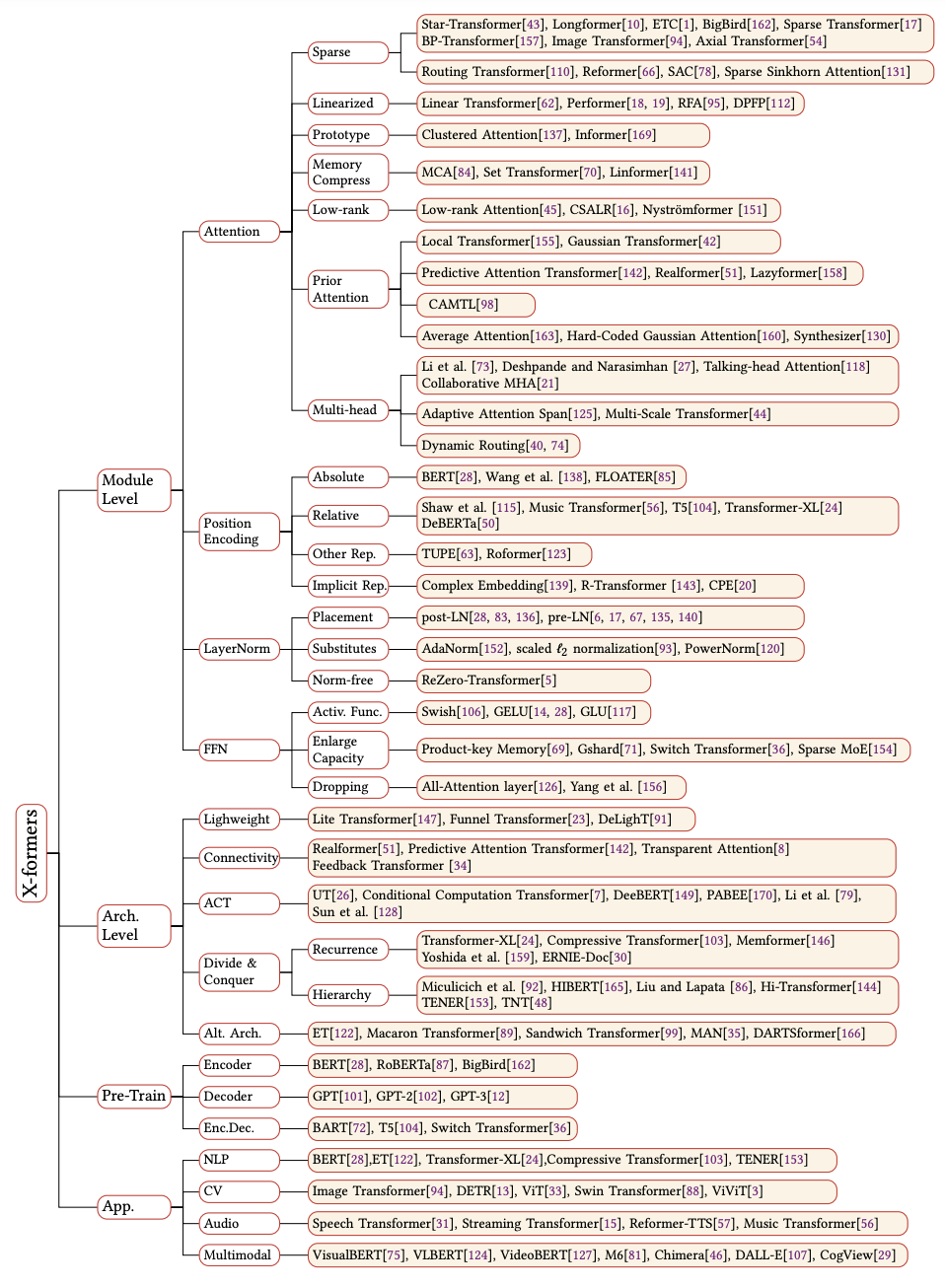
This paper presents a very comprehensive and detail review on variants of Transformer models. The authors categorize and organize their survey into architectural modification, pre-training, and application. Highly recommended reading for anyone who want to study various aspects of Transformer models.
Categorization of Transformer variants. Note the color grouping on Transformer module. Figure taken from (Lin et al., 2021).The taxonomy of Transformers introduced in the paper. Figure taken from (Lin et al., 2021).
At the end of the paper, the authors emphasis on several direction for further improvement of Transformer:
Lacks of theoretical analysis on Transformer models.
Better global interaction mechanism beyond attention. Few papers I mentioned in a blog post few weeks ago show some effort in this area.
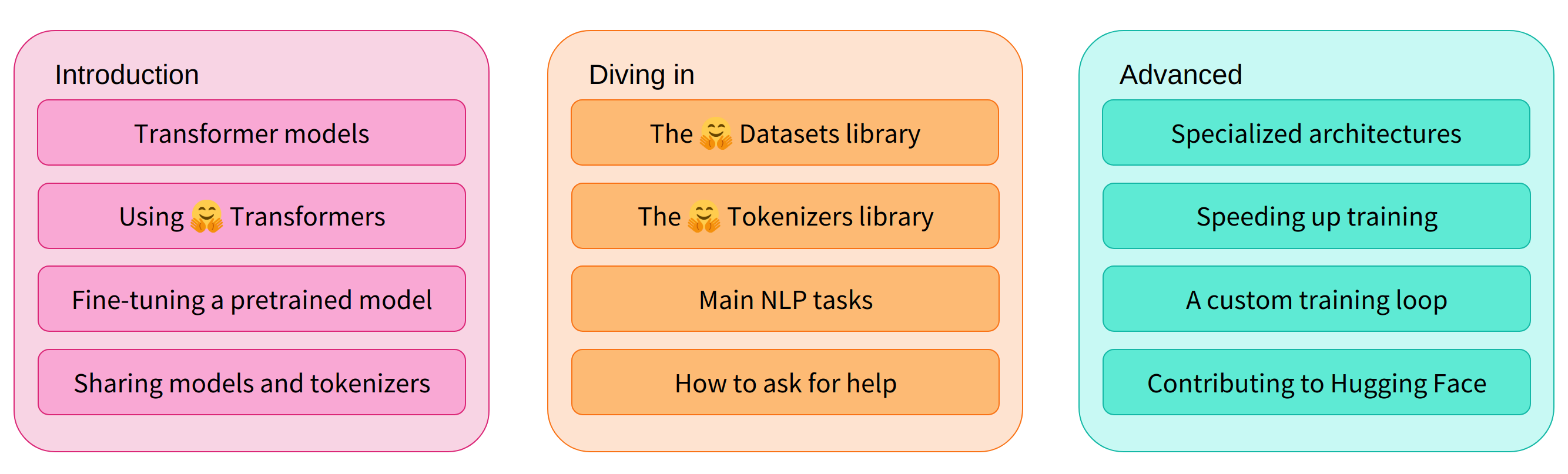
One of the most popular NLP libraries just released the first part of free Hugging Face course on Natural Language Processing using Hugging Face ecosystem. The first part focuses on the Transformer models in Hugging Face including on how to fine-tune and sharing the models.
Overview of Hugging Face course. Figure taken from the Hugging Face course website.
The second and third parts will focus on datasets and tokenizers libraries, and deep dive into NLP tasks and developing specialized architectures.
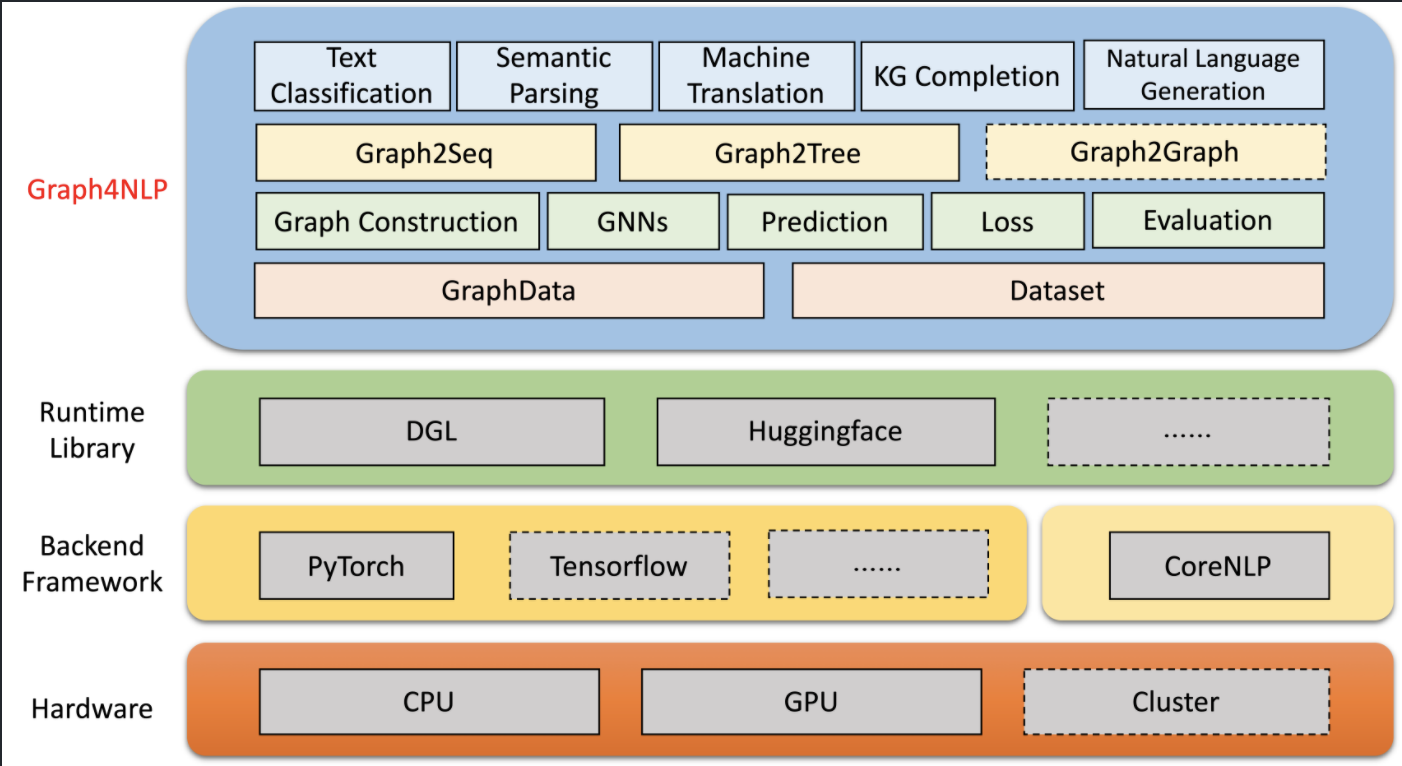
Graph4NLP is an easy-to-use Deep Learning on Graph library focusing on NLP research. It’s built upon highly-optimized runtime DGL (Deep Graph Library). This library helps users to use GNNs in various NLP tasks such as text classification, semantic parsing, neural machine translation, summarization, knowledge graph construction, natural language generation.
Graph4NLP architecture. Figure taken from Graph4NLP github page.
The figure below shows the computing flow of Graph4NLP which reflects the standard workflow to use graph-based deep learning approaches for NLP tasks.
Graph4NLP computing flow. Figure taken from Graph4NLP github page.