We have NAACL 2021 best paper, a great survey paper of Transformer models, a free NLP course, and an open source NLP library for Machine learning this week. Let’s take a look at them.
It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners [paper][blog]
GPT-3 model has shown its superior few-shot performance in many NLP tasks. However, GPT-3 is a gigantic model, and training GPT-3 needs huge computing power that is not practical for many people. This NAACL 2021 best paper proposes an effective alternative method to train a few-shot learner models using small language model. The main idea is reformulating tasks as cloze questions, and providing a gradient-based learning with few of these cloze questions training examples.

The algorithm is called Pattern-exploiting training (PET). This algorithm needs two components:
- Pattern: a conversion of input into a cloze question
- Verbalizer: an expression of the output using one or more words.
In the figure shown above, we convert sentence “Excellent pizza!” into “Excellent pizza! It was ____”. Then, we ask the model to verbalize “good” for positive sentiment, or “bad” for negative sentiment.
This paper also shows an extensive experiment to identify factors contributing to strong PET performance such as the choice of patterns, and verbalizers, the usage of both unlabeled and labeled data, and properties of the underlying language model.
A Survey of Transformers [paper]
This paper presents a very comprehensive and detail review on variants of Transformer models. The authors categorize and organize their survey into architectural modification, pre-training, and application. Highly recommended reading for anyone who want to study various aspects of Transformer models.
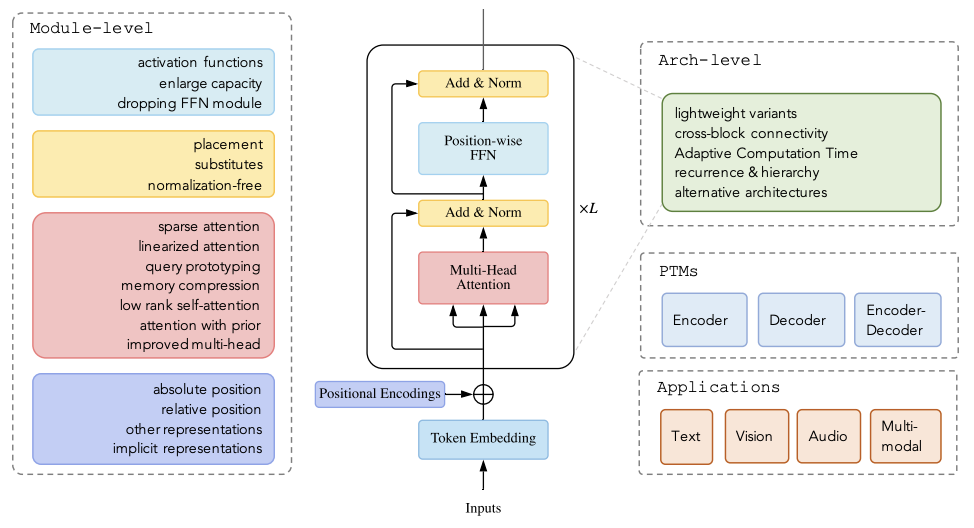
At the end of the paper, the authors emphasis on several direction for further improvement of Transformer:
- Lacks of theoretical analysis on Transformer models.
- Better global interaction mechanism beyond attention. Few papers I mentioned in a blog post few weeks ago show some effort in this area.
- Unified framework for multimodal data.
Hugging Face Course [website]
One of the most popular NLP libraries just released the first part of free Hugging Face course on Natural Language Processing using Hugging Face ecosystem. The first part focuses on the Transformer models in Hugging Face including on how to fine-tune and sharing the models.
The second and third parts will focus on datasets and tokenizers libraries, and deep dive into NLP tasks and developing specialized architectures.
Graph4NLP [github]
Graph4NLP is an easy-to-use Deep Learning on Graph library focusing on NLP research. It’s built upon highly-optimized runtime DGL (Deep Graph Library). This library helps users to use GNNs in various NLP tasks such as text classification, semantic parsing, neural machine translation, summarization, knowledge graph construction, natural language generation.
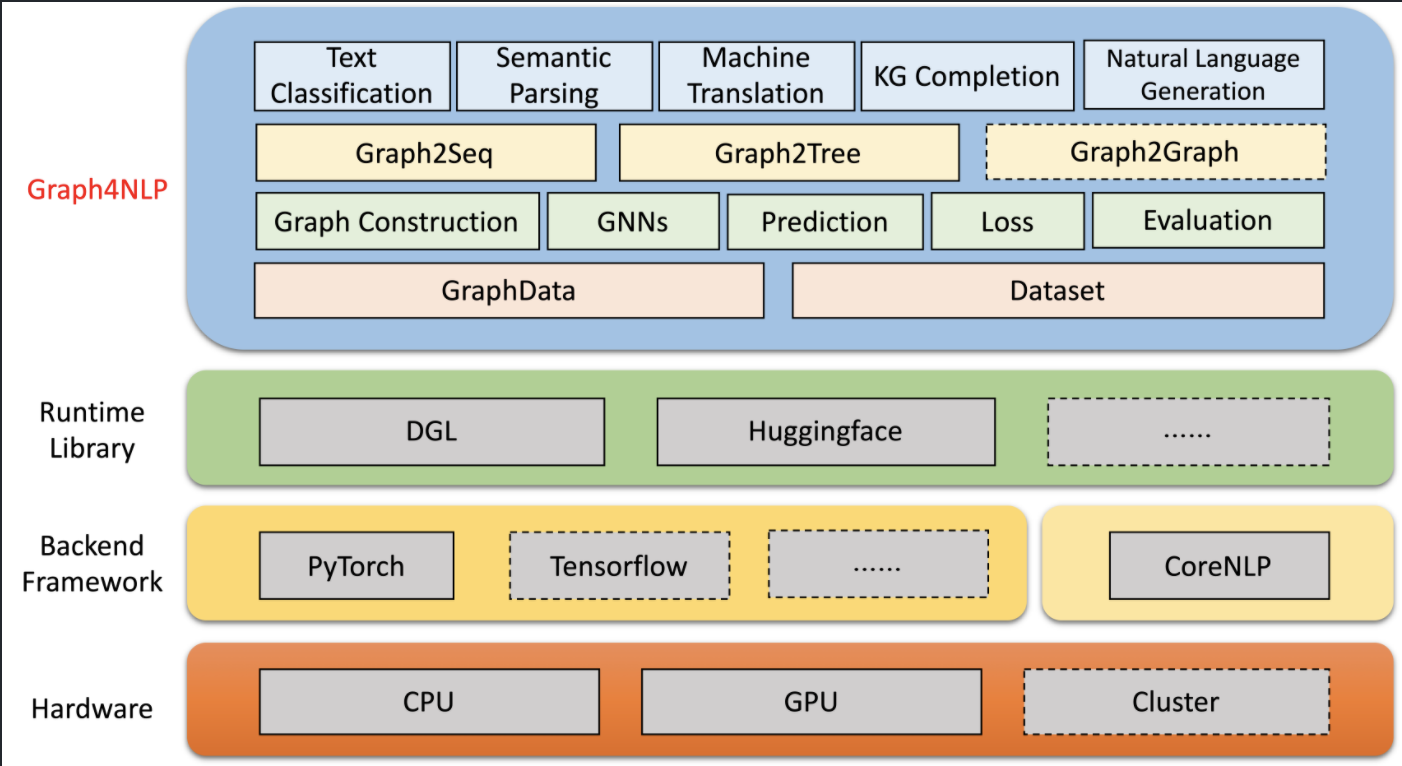
The figure below shows the computing flow of Graph4NLP which reflects the standard workflow to use graph-based deep learning approaches for NLP tasks.

More in-depth tutorial including recent advances on Deep Learning on Graphs for NLP can be read their NAACL 2021 Deep Learning on Graphs for natural language processing tutorial slides.
That’s all for this week. How’s your machine learning week? Stay safe and see you next week.