2018 has been an exciting year for me. I encounter, explore and learn many exciting ideas and efforts in NLP. In this post, I briefly summarize NLP developments and efforts that excite me in 2018.
1. Translation without Parallel Data
Recent successes in unpaired image-to-image translation such as DiscoGAN , and CycleGAN inspire work on similar goal in NLP, more specifically in the area of machine translation and text generation. In unpaired translation setting, we eliminate the need of building parallel corpora which is very tedious and slow process.
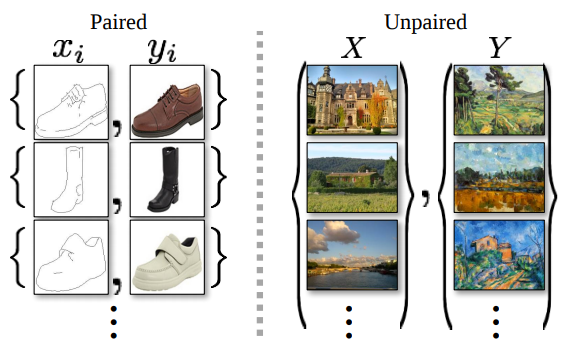
When dealing with unpaired translation setting, a machine learning model needs to discover cross-domain alignment without supervision. In the absence of correspondence mapping information, one trick that has been shown to be effective is utilizing back-translation. In back-translation, after we translate from source to target, we translate the target back to the source. Many models utilize this back-translated source as reference to guide the translation quality.
Learning from unpaired training data is perfect fit for unsupervised machine translation system where we only have access to monolingual corpora. Recent works by (Lample et al., 2018a; Lample et al., 2018b) show that good initialization, language modeling, and back-translation are three principles for success in building unsupervised machine translation model.
Beside language translation, this approach has been used in many text generation problem such as author attribute anonymity (Shetty et al., 2018), text generation with attribute control (Logeswaran et al., 2018), and text style transfer (Zhang et al., 2018).
2. Text Style Transfer
Motivated by growing interest in Neural Style Transfer in computer vision (see review by Jing et al., 2018), there are a number of recent work on style transfer for text generation. Text style transfer aims to rewrite a given text in a different linguistic style, while at the same time preserving the content of original text.
Many works on text style transfer formulate the problem by learning disentangled latent representation (Bengio et al., 2014) from input text, producing a latent representation consists of content and style component. Using this representation, one can easily control and modify the style component, while keeping the content representation intact, to generate output text. We hope that the generated output has the same content, but in different style.
Adversarial autoencoder (Makhzani et al., 2016) is the most popular choice to learn disentangled latent representation for text style transfer (Shen et al., 2017; Fu et al., 2018; Yang et al., 2018; Zhao et al., 2018; Zhao et al., 2018). Another approach leverages the idea of back-translation from unsupervised machine translation (Prabhumoye et al., 2018; Subramanian et al., 2018). The style transfer includes sentiment modification, translate offensive sentences to non-offensive sentences, and paper-news title transfer.

Despite many work on text style transfer, a fundamental question still remains: what constitutes a style? Is sentence modification a good example of text style transfer? Tikhonov and Yamshchikov (2018) suggest that style has to be orthogonal to semantics, and thus any semantically relevant information could be expressed in any style. Furthermore, evaluation on generated text also remains a big question. How do we accurately measure the style, while at the same time ensure the meaning is preserved? Current evaluations are mainly based on style classifier accuracy and human evaluation. Pang and Gimpel (2018) suggest that style classifier accuracy alone it not sufficient to evaluate text style transfer, and propose to combine style classifier accuracy with semantic similarity and fluency metrics to better assess non-parallel textual transfer.
3. Deep Contextual Representations
Word embedding has been an important building block of many deep learning models for NLP tasks. Word embedding encodes information from each word in input text to be processed by deep learning models. Many methods such as word2vec and glove, have been developed to generate word embedding that captures linguistic contexts of words. Recent work on word embedding involves refining (retrofit) learned word embedding to external information such as semantic lexicons (Faruqui et al., 2015) and knowledge graph (Lengerich et al., 2018).
Traditionally, word embedding vectors are pre-trained using shallow neural network on language modeling task. Using large general purpose corpora such as wikipedia or Google news, one can learn good embedding vectors to be used for many NLP tasks. In 2018, we see more efforts in exploiting contextual information in deep neural network, and thus the word representations are derived from multiple layer in deep networks. OpenAi GPT (Radford et al., 2018), ELMo (Peters et al., 2018), and BERT (Devlin et al., 2018) show deep contextual representations give large improvement on broad range of NLP tasks.
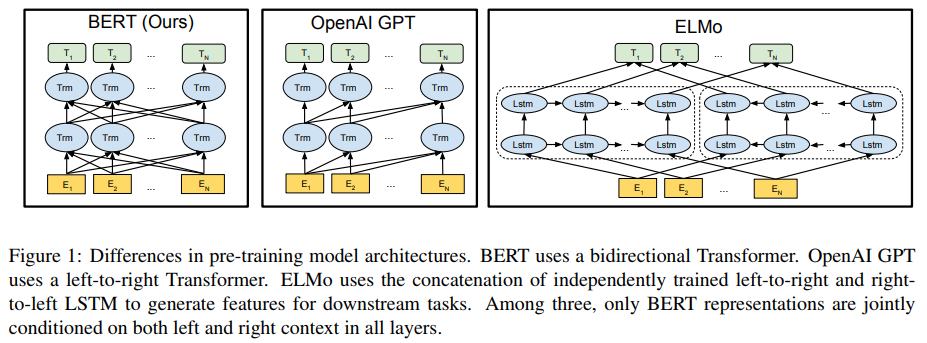
Jay Alammar has a great blog post in explaining deep contextual representations. I highly recommend to read his post to better understand this concept.
4. Information Extraction for Scientific Literature
With constant increase of scientific papers being published every day, there are growing needs of a scientific knowledge discovery tool. Information extraction from scientific papers becomes an important application of natural language technology. Meta, a scientific discovery tool for biomedical research, extracts various medical concepts, and makes them available to search and follow. Allen AI team behind SemanticScholar develops a scalable system to construct literature graph in order to facilitate algoritmic discovery in the scientific literature (Ammar et al., 2018). SemEval 2018 also has one track for this task. SciIE (Luan et al., 2018) employs multitask approach for identifying entities, relations, and coreference in scientific papers.
In the area of social science, NYU Coleridge Initiative hosts Rich Context Competition which aims to automatically discover research datasets, methods, and fields in social science research publications. The competition finalists (from GESIS, KAIST, Paderborn University, and Allen AI) will be presenting their work in Rich Context Competition Workshop on 15 February 2019. They will webcast the workshop. Register here! 🙂
Another related event in this area, collocated with NAACL 2019 is Extracting Structured Knowledge from Scientific Publications (ESSP) workshop.
5. Datasets, Datasets, and Datasets
We see the birth of more and more datasets for more specific and challenging NLP tasks in 2018. 15 new datasets were presented in EMNLP 2018 alone (Sebastian Ruder summarizes them in his EMNLP 2018 highlight). There are also NLP benchmarks based on established datasets for studying and evaluating NLP models:
- GLUE benchmark (Wang et al., 2018): a benchmark consists of nine sentence- and sentence-pair language understanding tasks, i.e. CoLA, SST-2, MRPC, STS-B, QQP, MNLI, QNLI, RTE, and WNLI.
- decaNLP (McCann et al., 2018): a benchmark for a multitask NLP challenge consisting of question answering, machine translation, summarization, natural language inference, sentiment analysis, semantic role labeling, relation extraction, goal-oriented dialogue, semantic parsing, and commonsense reasoning.
More and more datasets will definitely trigger rapid NLP advancement in solving various NLP tasks. A nice crowdsourcing effort led by Sebastian Ruder to track NLP progress can be seen at nlpprogress.com.
There are some great AI 2018 roundups from various blog posts which inspire me to write this blog post. I highly recommend you to read these posts:
- Google AI’s research efforts in 2018
- Xavier Amatriain’s AI/ML 2018 roundup
- Sebastian Ruder’s 10 exciting ideas of 2018 in NLP
- FAIR highlights at their 5th anniversary in December 2018
- Overview of 14 NLP research highlight in 2018 by Mariya Yao
Looking forward to more exciting 2019.