Geometric Deep Learning (DGL) course publishes great course materials including slides and video recording on the topic of Geometric Foundations of Deep Learning (which I shared some time ago). The course was delivered as part of African Master’s in Machine Intelligence (AMMI 2021). I will take time to go through all the lecture videos of this course.
BERTopic is a topic modeling technique that performs a density-based clustering on document representation (encoded using a transformer-based model). BERTopic utilizes class-based TF-IDF (c-TF-IDF) to get important words on each topic.
This library provides easy-to-use API to perform BERTopic, and visualize topics. In addition, it also supports various pre-trained models such as Sentence Transformer, Flair (allows you to use Huggingface pre-trained transformer models), Spacy, Gensim, and Universal Sentence Encoder (USE).
How to avoid machine learning pitfalls: a guide for academic researchers [paper]
This paper discusses common mistakes when using machine learning techniques, and how to avoid them. The paper is very suitable to anyone new in machine learning area. It covers pitfalls in every stage of machine learning development including data preparation, model development, evaluation to reporting. Here is the outline of the paper.
The content of the paper.
That’s all for this week. Stay safe and see you next week.
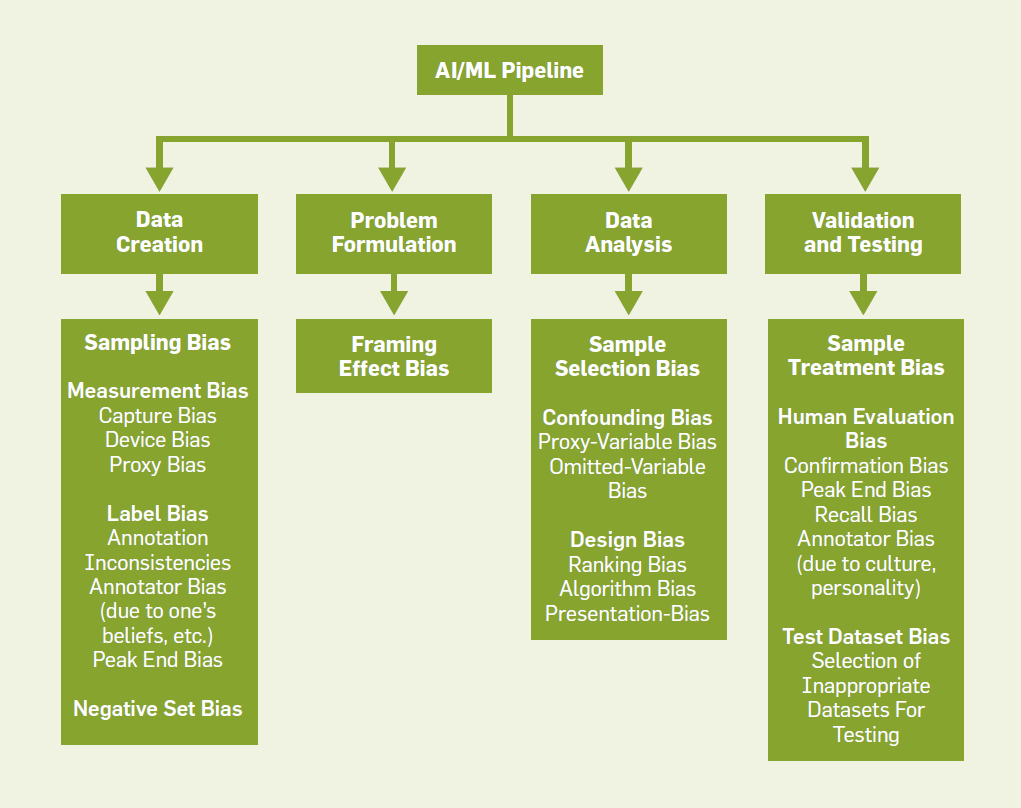
For this week in machine learning, we look into biases in AI system from CACM (Communication of ACM) article for August 2021. The article nicely explains overview of biases that can present in our AI systems. Here are my short note.
Machine learning is a complex system, and it involves learning from a large dataset with a predefined objective function. It is well-known too that Machine learning systems exhibit biases that comes from every part of the machine learning pipeline: from dataset development to problem formulation to algorithm development to evaluation stage.
Detecting, measuring, and mitigating biases in machine learning system, and furthermore, developing fair AI algorithm are not easy and still active research areas. This article provides a taxonomy of biases in the machine learning pipeline.
Machine learning pipeline begins with dataset creation, and this process includes data collection, and data annotation. During this process, we may encounter 4 types of biases:
Sampling bias: caused by selecting particular types of instances more than others.
Measurement bias: caused by errors in human measurement or due to certain intrinsic habits of people in capturing data.
Label bias: associated with inconsistencies in the labeling process.
Negative set bias: caused by not having enough negative samples.
Next stage is problem formulation. In this stage, biases are cause by how a problem is defined. For example, in creditworthiness prediction using AI, the problem can be formulated based on various business reasons (such as maximize profit margin) other than fairness and discrimination.
On algorithm and data analysis, several types of biases that potentially can occur in your system:
Sample selection bias: caused by selection of data instances as a result of conditioning on some variables in the dataset
Confounding bias: it happens because the machine learning algorithm does not take into account all the information in the data. Two types of confounding bias:
omitted variable bias
proxy variable bias, for example zip code might be indicative of race
Design bias: caused by the limitation of the algorithm or other constraints on the system. It could be in the form of algorithm bias, ranking bias, or presentation bias.
Here are several types of biases on the evaluation and validation stage:
Human evaluation bias: caused by human evaluator in validating the machine learning performance.
Sample treatment bias: selected test set for machine learning evaluation may be biased.
Validation and test dataset bias: due to selection of inappropriate dataset for testing.
Beside the taxonomy of bias types, the authors also give some practical guidelines for machine learning developer:
Domain-specific knowledge is crucial in defining and detecting bias.
It is important to understand features that are sensitive to the application.
Datasets used for analysis should be representative of the true population under consideration, as much as possible.
Have an appropriate standard for data annotation to get consistent labels.
Identify all features that may be associated with the target feature is important. Features that are associated with both input and output can lead to biased estimates.
Restricting to some subset of the dataset can lead to unwanted sample selection bias.
Avoid sample treatment bias when evaluating machine learning performance.
Living Analytics Research Centre (LARC) and Elastic gave a workshop titled Elasticsearch: You know, for search! and more! at FOSSASIA 2016 last week. It’s an introduction to Elasticsearch, and we shared our experience in using Elasticsearch at LARC. The crowd was great, and we had a bunch of questions related to Elasticsearch, and particularly how we utilize Elaticsearch in our lab. Here is our slide deck:
And here is the slide deck from Elastic (by @medcl):