I share few interesting open source projects related to machine learning deployment, neural search framework, and flexible machine learning data structure for this week in machine learning.
Parallelformers: An Efficient Model Parallelization Toolkit for Deployment [github][documentation]
Parallelformers helps us to deploy most big transformer-based model on multiple gpus for inference. It is designed to make model parallelization easier, and we can parallelize many Huggingface transformer models with a single line of code.
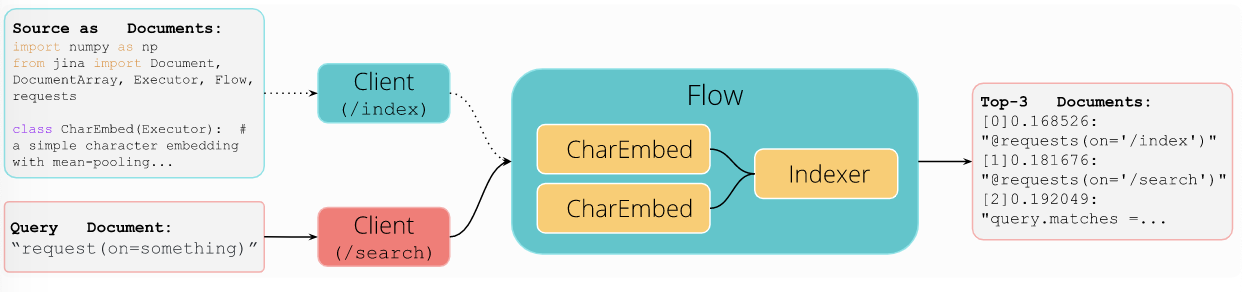
Jina: Cloud-native neural search framework for any kind of Data [github]
Building a search engine is hard, especially when our data are not text data. Neural search leverages on state-of-the art deep neural network to perform information retrieval, and it enables retrieval of any kinds of structured data such as images, video, audio, 3D mesh, etc. Jina is a neural search framework allowing us to build neural search engine as a service quickly. It employs distributed architecture, and cloud-native by design. Take a look at its quick demo.
Meerkat: Flexible data structure for complex machine learning datasets [github][blog]
With various type of machine learning data (such as images, graphs, videos, time-series), a simple data abstraction for data wrangling greatly helps ML practitioners to interact with high-dimensional, and multi-modal data. Inspired by Panda DataFrame and combined with the capability of from recent data abstraction in deep learning framework such as PyTorch Dataset and Tensorflow Dataset), Meerkat DataPanel provides a simple data abstraction that offers best of the both world. Meerkat DataPanel supports:
- Complex datatype (for example: images, graph, videos, time-series)
- Datasets that are larger-than-RAM with efficient I/O under-the-hood
- Multi-modal datasets
- Data creation and manipulation
- Data selection
- Inspection in interactive environment
Note that PyTorch Dataset and Tensorflow Dataset support number 1-3 in above list, whereas Panda DataFrame supports number 4-6 in above list. Read their blog for more detail examples on how Meerkat DataPanel helps us wrangle our datasets.
That’s all for this week. See you next week.