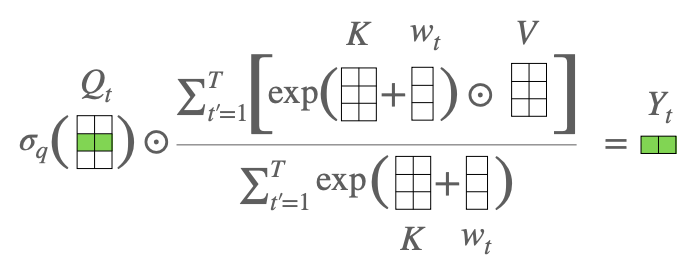My machine learning this week is about a long text generation. I also encounter an open source computer vision framework for self-supervised learning, and a resource on reproducible machine learning course. Let’s take a look.
Progressive Generation of Long Text with Pretrained Language Models [paper][github]
When generating long text, current large-scale fine-tuned pretrained language model exhibits some issues such as excessive repetitiveness or incoherence between sentences that are far apart. Another strategy for long text generation is using content planning before the actual text generation. The content planning in this strategy may require another task such as summarization or semantic role labeling which demands another resources and labeled data. Another more recent non-monotonic generation approaches also require specialized architectures, making them hard to integrate with the existing pretrained language models.
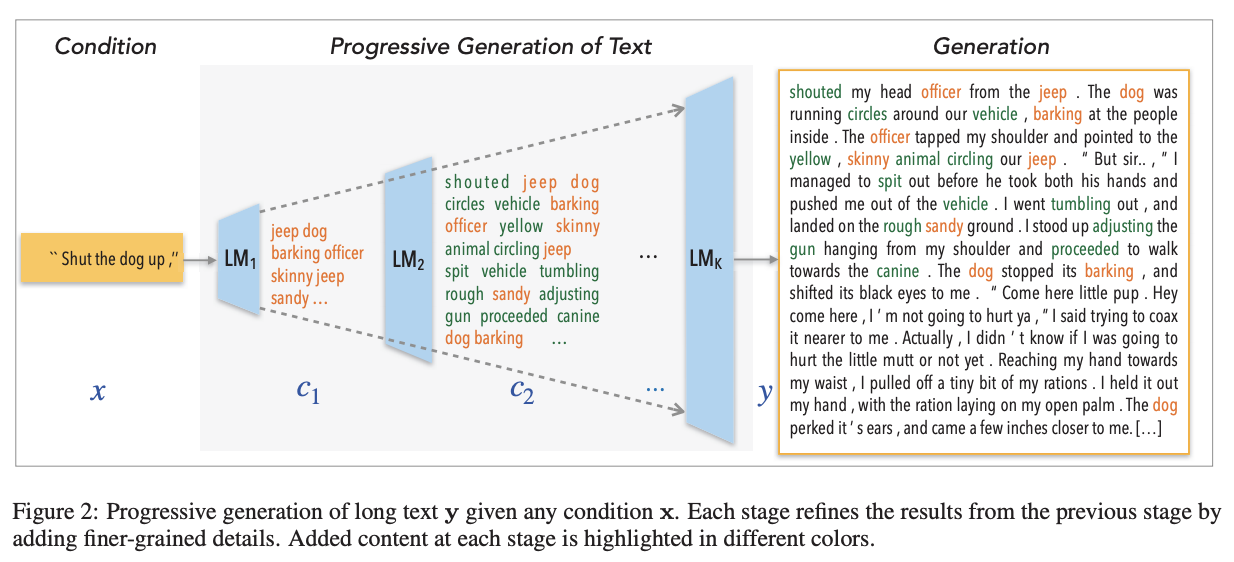
This paper proposes a simple strategy for long text generation (~1000 tokens) which can still leverage on the existing pretrained models. The main idea is to progressively generate text in multiple stages, breaking the complex text generation into multiple easier steps, from a skeleton to a full passage. Each stage refines the output from the previous stage by adding finer details. The algorithm is called Progressive Generation (ProGen).
Progressive Generation (ProGen) for long text generation. Figure taken from (Tan et al., 2021).
To achieve this mechanism, ProGen uses limited vocabularies on earlier stages based on the word importance, for example the first stage only uses 15% of the most important words in the corpus, the second stage only uses 20% of the most important words in the corpus, and so on. Then, the training data for each stage can be easily constructed by dropping all tokens that do not belong to the vocabularies in the particular stage. We can add noises to improve robustness and reducing data bias. Finally, we fine-tune a pretrain language model on each stage.
ProGen algorithm. Algorithm section taken from (Tan et al., 2021).
We can see that ProGen is conceptually very similar to non-monotonic generation. But, the generation is still performed in autoregressive, left-to-right fashion, making it more compatible with the existing pretrained language models. Compare to content planning strategy, ProGen has more flexible intermediate stages. Typical content planning strategies only have two stages.
Example of 3-stage long text generation on CNN News domain. Figure taken from (Tan et al., 2021).
Lightly is computer vision framework for self-supervised learning. This framework helps us to curate our dataset better, find edge cases, and improve data quality. The framework supports several models such as MoCo, SimCLR, SimSiam, BarlowTwins, BYOL, and NNCLR.
I stumble upon a great resource on a practical reproducible deep learning course by Simone Scardapane. The course content covers tools that you need for reproducible deep learning workflow such as git, hydra, data version control, docker, weight & biases, and continuous integration. Great course by Simone.
Reproducible Deep Learning Course
That’s all for this week. How’s your machine learning week? Leave a comment below.
Hello, my machine learning reading this week focuses on alternative architectures to self-attention in Transformer. In particular, I read three papers: FNet, gMLP, and Attention-free Transformer (AFT). Let’s see the main ideas in these papers.
FNet: Mixing Tokens with Fourier Transforms [paper]
Self-attention mechanism in Transformer architecture serves as an inductive bias, connecting each token in the input with weights to every other tokens. This mechanism has shown very effective and achieved many state of the art results in many NLP tasks. However, the standard self-attention mechanism requires quadratic time and memory with respect to sequence length, limiting its applicability to long sequences. There are several effort to reduce this quadratic complexity by sparsifying or compressing the attention matrix (see Tay et al., 2020 on Efficient Transformer survey).
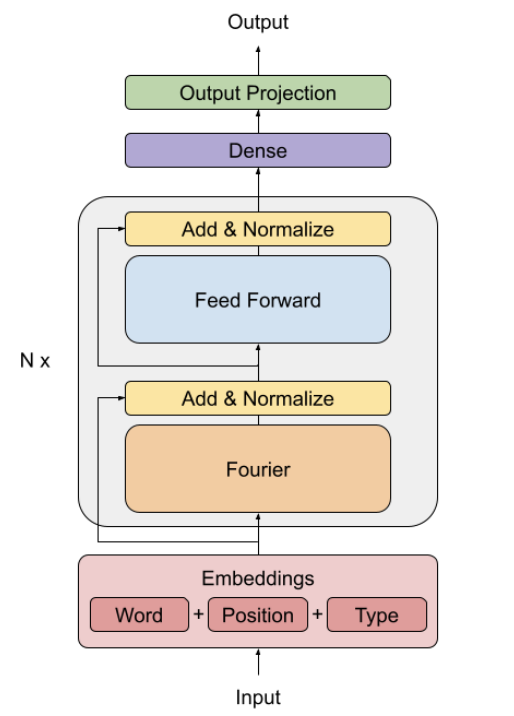
This paper proposes a different approach, replacing self-attention sublayer in transformer architecture with Fourier transform. Fourier transform can be computed fast on GPUs and TPUs, and it does not carry any learned weight, making it smaller than standard Transformer. Thus, the architecture, namely FNet, is faster and using less memory than standard Transformer. FNet is capable to handle long sequences.
FNet encoder architecture, replacing self-attention block with Fourier transformation block. Figure taken from (Lee-Thorp et al., 2021).
The authors also have another model (called linear encoder), replacing self-attention sublayer with two linear sublayers. It is originally introduced as a baseline to the FNet, but it surprisingly turns out that the linear encoder also performs very well too. They also experiment with hybrid FNet attention model by replacing final two Fourier sublayers of FNet with self-attention sublayers. The hybrid model increases the performance of the base FNet model with small additional training cost. The improvement indicates that self-attention is important, but we do not need a big self-attention sublayers to archive strong performance. Here is a great YouTube video explaining FNet by Yannic Kilcher.
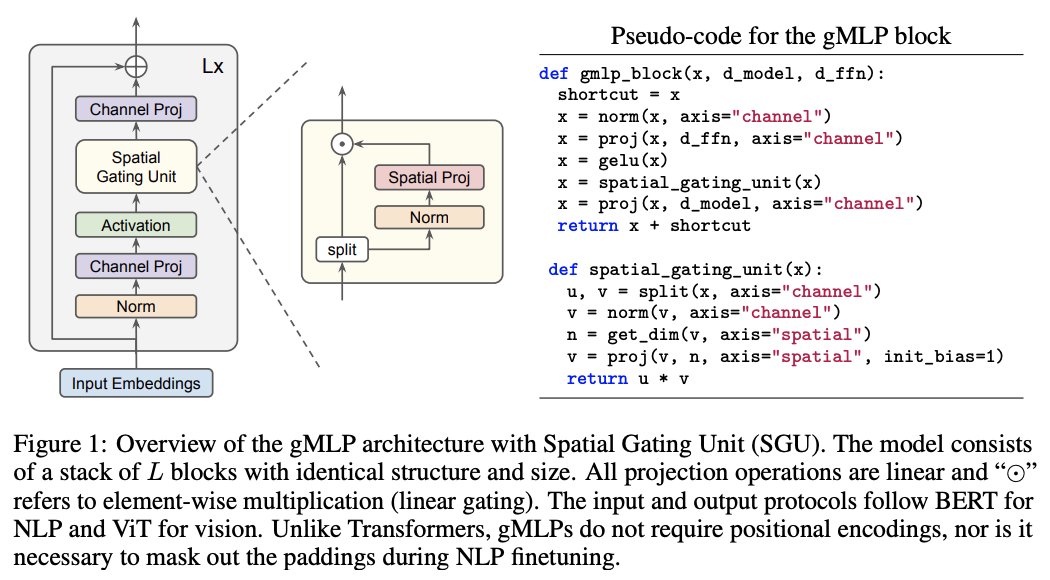
gMLP is another approach to replace Transformer using MLP layers with gating. gMLP consists of channel projection and spatial projection with multiplicative gating. This alternative is simpler and cheaper to compute than self-attention layer in Transformer.
The main component of gMLP is spatial gating unit which captures spatial interaction, offering an alternative mechanism to capture high-order relationships. The authors of this paper perform several experiments comparing gMLP with Vision Transformer (ViT), DeIT (ViT with improved regularization), and BERT. They also study the importance of gating in gMLP, the scaling properties of gMLP, and the usefulness of adding tiny self-attention in gMLP. Attaching a tiny single-head self-attention to the gating function of gMLP improves gMLP to outperform Transformer of similar capacity.
aMLP architecture: gMLP with tiny attention. Figure taken from (Liu et al., 2021).
This paper replaces standard multi-head attention in Transformer with more efficient element-wise operation between query and combined key and value. This replacement improves the computation to linear time and space complexity with respect to input and model size. Attention-Free Transformer (AFT) performs weighted average of values (V) combined with the keys (K) and a set of learned pairwise position biases.
Illustration of Attention-Free Transformer (AFT). Figure taken from (Zhai et al., 2021).
These few papers show recent developments to improve the efficiency of Transformer models by modifying or replacing the most expensive component in Transformer: self-attention layer.
That’s all for this week. Enjoy and see you next week!
This week in machine learning is filled with GAN-related papers from Nvidia. DatasetGAN shows the usefulness of GAN (Generative Adversarial Network) in generating simulated training data at scale. Another paper from Nvidia shows a nice GAN application for controllable 3D rendering from a single 2D image. Let’s take a look at the idea on each paper.
DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort [website][paper]
The availability of labeled data is one big bottleneck to have an effective machine learning system. There are huge amount of unlabeled data out there, but high-quality labeled datasets are still limited because it takes huge amount of time, human resources, and money to create such datasets.
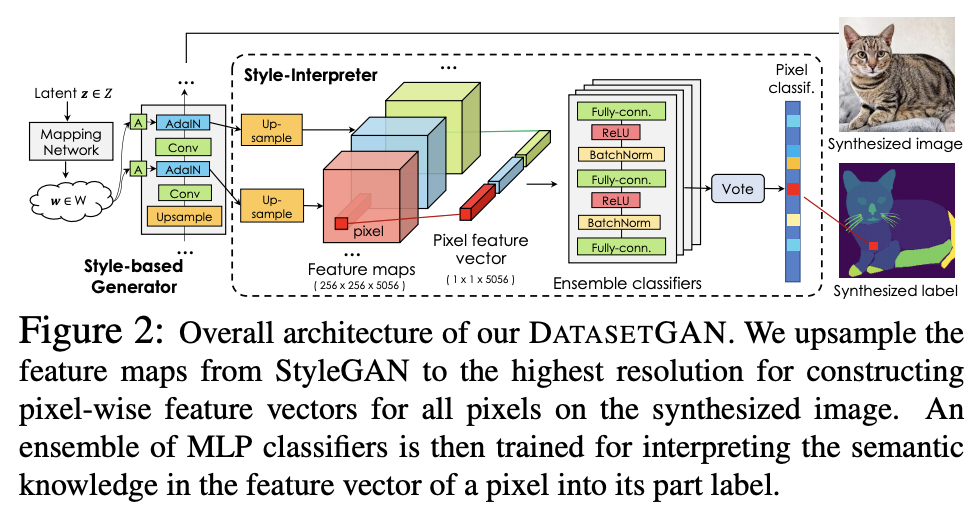
DatasetGAN is simple semi-supervised approach to synthesize massive large high-quality dataset with minimal human annotation. It shows that we can synthesize high-quality semantically segmented images using GAN, utilizing semantic knowledge (such as viewpoint, object identity) in its high dimensional latent space.
DatasetGAN generates large high-quality labeled image datasets leveraging StyleGAN and a handful human-annotated images. Figure taken from (Zhang et al., 2021).
DatasetGAN uses StyleGAN as the rendering engine, and then adding style-interpreter component to synthesize labels from StyleGAN latent vectors. Style interpreter consists of an ensemble of MLP classifiers to predict the label on each pixel based on the features from the upsampled StyleGAN latent vectors.
The authors perform experiments on bedrooms, cars, heads, birds, and cats images for semantic segmentation, and keypoint detection. They also showcase an application of this approach to perform animatable 3D object reconstruction from an image.
Image GANs Meet Differentiable Rendering for Inverse Graphics and Interpretable 3D Neural Rendering [paper][blog]
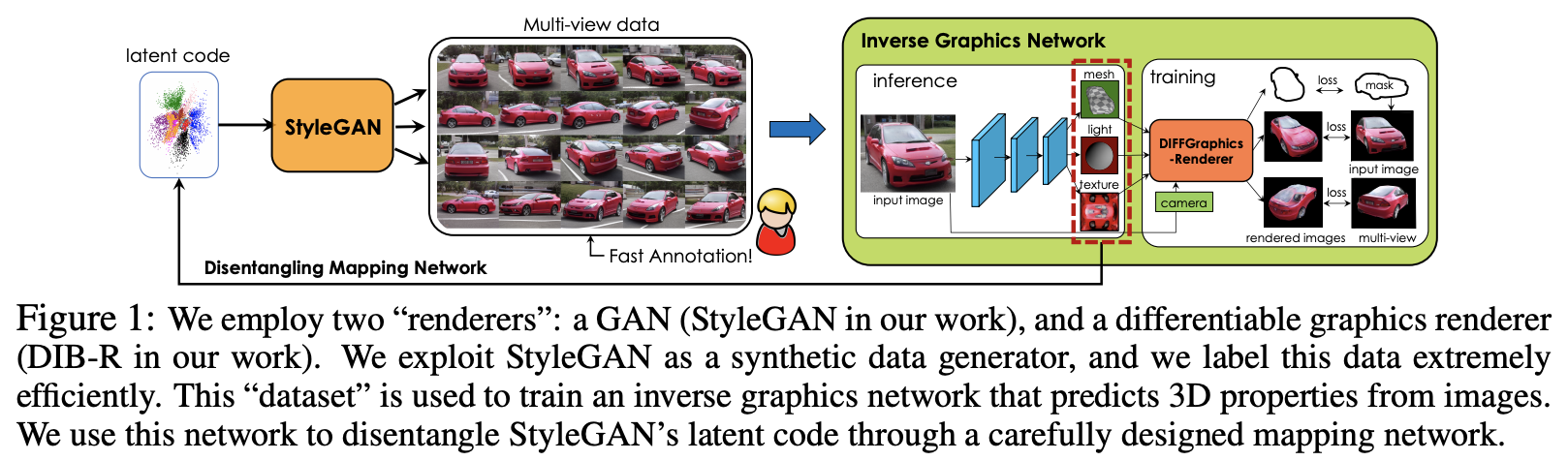
This paper reconstructs 3D objects from 2D images, often known as inverse graphics task. Most of existing approaches rely on the availability 3D labels to train a model. The authors of this paper present a way to extracts and disentangle 3D knowledge learned from GAN using differentiable rendering. Using this approach, they are able to obtain high-quality 3D rendering with low annotation effort.
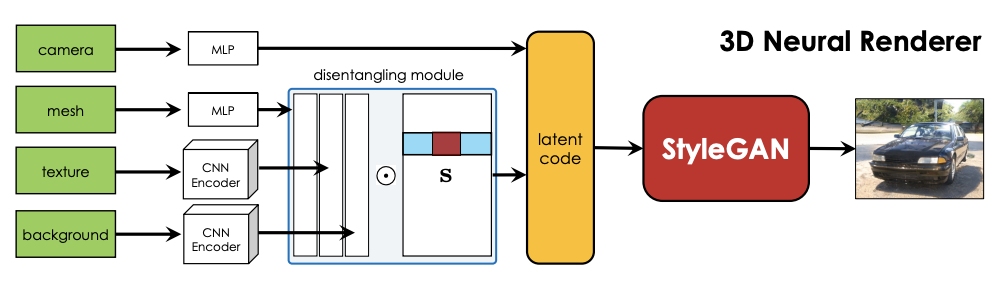
StyleGAN to generate synthetic data efficiently, and Inverse Graphic Network to predicts 3D properties from images. Figure taken from (Zhang et al., 2021).
The approach aims to disentangle camera viewpoints, shapes, texture, light, and background. It combines two state-of-the art renderer as main components. In the first component, they utilize StyleGAN as multi-view data generator. Each layer in StyleGAN controls different image attribute, for example early layers control viewpoint, while intermediate and high layers control shape, texture, and background. They leverage on this knowledge, and uses first four layers of StyleGAN to disentangle camera viewpoints.
The second component is inverse graphics neural network DIB-R (Chen et al., 2019) to predict 3D shapes and texture from an image. This model enables them to detect 3D properties from image. This 3D properties are then mapped back into StyleGAN latent vectors, allowing them to control the StyleGAN rendering based on certain properties.
3D properties are mapped into StyleGAN, enabling controllable 3D rendering. Figure taken from (Zhang et al., 2021).
The model is still unable to predict correct lighting, and disentangling background is still a challenge. Moreover, predicting shapes of out-of-distribution objects (such as Batmobile and Flintstone car) is also another significant challenge.
3D reconstruction from monocular photograph.
That’s all for this week. Stay safe, and see you next week!
Hello everyone, I read a survey paper on number representation in NLP, encounter a GPT-3 replica model in huggingface model hub, and project Starline. Here few short notes on those.
Representing Numbers in NLP: a Survey and a Vision [paper]
Numbers are important and integral part of text, and yet numbers rarely get special consideration when processing text. Many NLP systems are commonly treated numbers as words, and subword tokenization such as BPE breaks numbers into arbitrary tokens, for example 1234 might be splitted into 1-234 or 12-34 or 123-4.
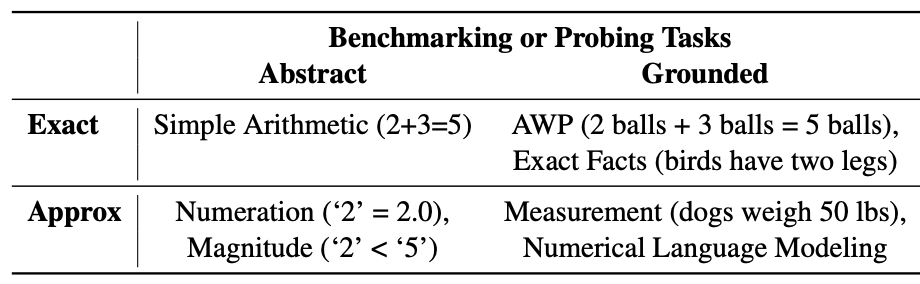
This paper surveys recent numeracy work in NLP and categorized them into seven numeracy tasks:
Simple arithmetic: arithmetic operation such as addition, subtraction over number alone.
Numeration: decoding a string form to its numeric value.
Magnitude comparison: ability to perform comparison on two or more numbers.
Arithmetic word problems: ability to perform simple arithmetic from a composition.
Exact facts: understanding numbers in commonsense knowledge.
Measurement estimation: approximately guess measure of objects along certain dimensions.
Numerical language modeling: making numeric predictions in completing text.
Numeracy tasks categorized into granularity and units. into Table taken from (Thawani et al., 2021).
The numeracy tasks are categorized following two dimensions:
Granularity. Whether the encoding of the number is exact or approximate.
Units. Whether the numbers are abstract or grounded.
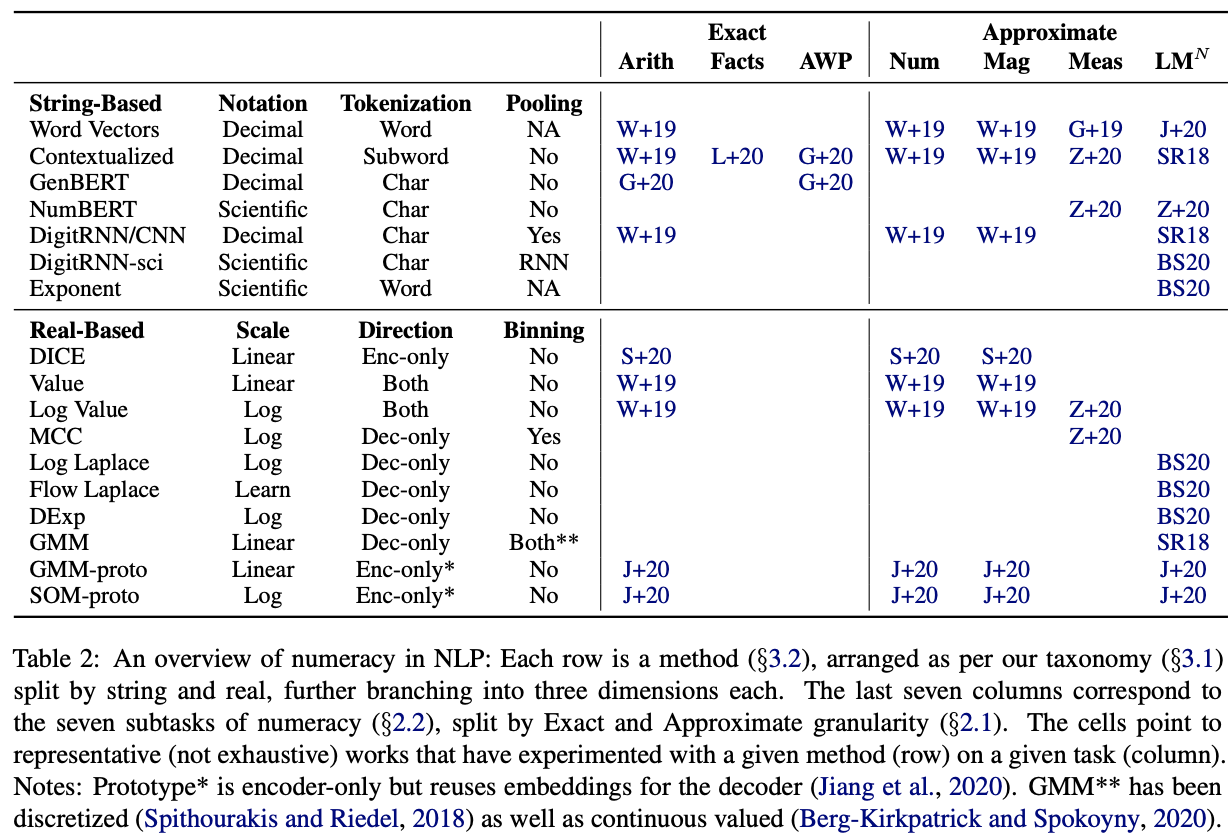
The author groups number representation into string-based and real-based representation. String-based representation treat numbers as strings, with several tweaks. Real-based representation performs computation using the numerical value of the number. Detail summary on each representation can be read in the paper.
The authors present few practical takeaways to guide the design of number representation:
For string-based representation:
Scientific notation is superior to decimal notation
Character level tokenization outperforms subword level tokenization.
For real-based representation:
Log scale is preferred over linear scale as inspired by cognitive science literature (but it lacks of rigorous study)
Binning (dense cross entropy loss) works better than continuous value prediction (MAE loss)
They also call for unified and more holistic solution to numeracy. This involves a benchmark covering different numeracy subtasks to incentive research progress in numeracy.
GPT-Neo: GPT-3 Replica by EleutherAI [model][article]
OpenAI GPT-3 has been powering many applications in various domains from creativity to productivity. Through OpenAI API, GPT-3 generates about 4.5 billions words per day. However, access to the OpenAI API is not free and still very limited to few companies and developers. And, training GPT-3 from scratch demands a lot of computing power that most people cannot afford.
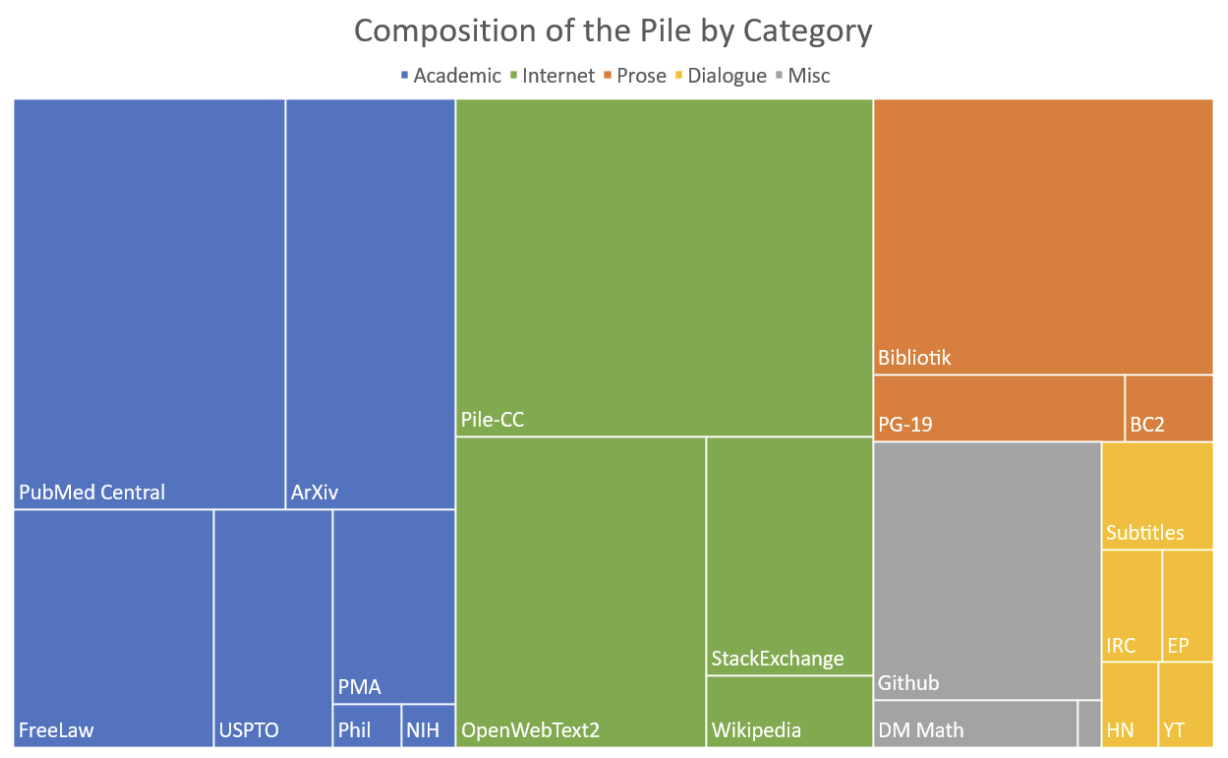
EleutherAI replicates GPT-3 architecture and trains the model on the Pile dataset. The Pile dataset is 825GB open source data for language modeling, combining texts from 22 sources such as English Wikipedia, OpenWebText2, PubMed Central, ArXiv, Github, Stack Exchange, Ubuntu IRC, and the US Patent and Trademark Office.
Treemap of Pile data sources showing size of each sources. Figure taken from (Gao et al., 2020).
The trained model is called GPT-Neo. The model has 2.7B parameters, and it is comparable to the smallest GPT-3 model. This model is a great free alternative to GPT-3, and it is available in the huggingface model hub.
Imagine having a long-distance conversation with your loved one, but you can see the person in real-life size, and three dimensions though a sort of magic windows. Google research applies technologies in computer vision, machine learning, spatial audio and real time compression, as well as light field display system to create a magic window that gives a sense of volume and depth without the needs for additional headsets or glasses. The result is a feeling of a person right in front of you, just like he/she is right there.
Project Starline combines 3D imaging, real time compression, and 3D display to create “Magic Window”
That’s all for this week. Stay safe and see you next week!
Hello! Hope you have a great week. I encounter an interesting machine learning papers, one course and one open source project this week:
Emerging Properties in Self-supervised Vision Transformers [paper][github][blog post]
Self-supervised Vision Transformer with no supervision. Figure taken from (Caron et al., 2021).
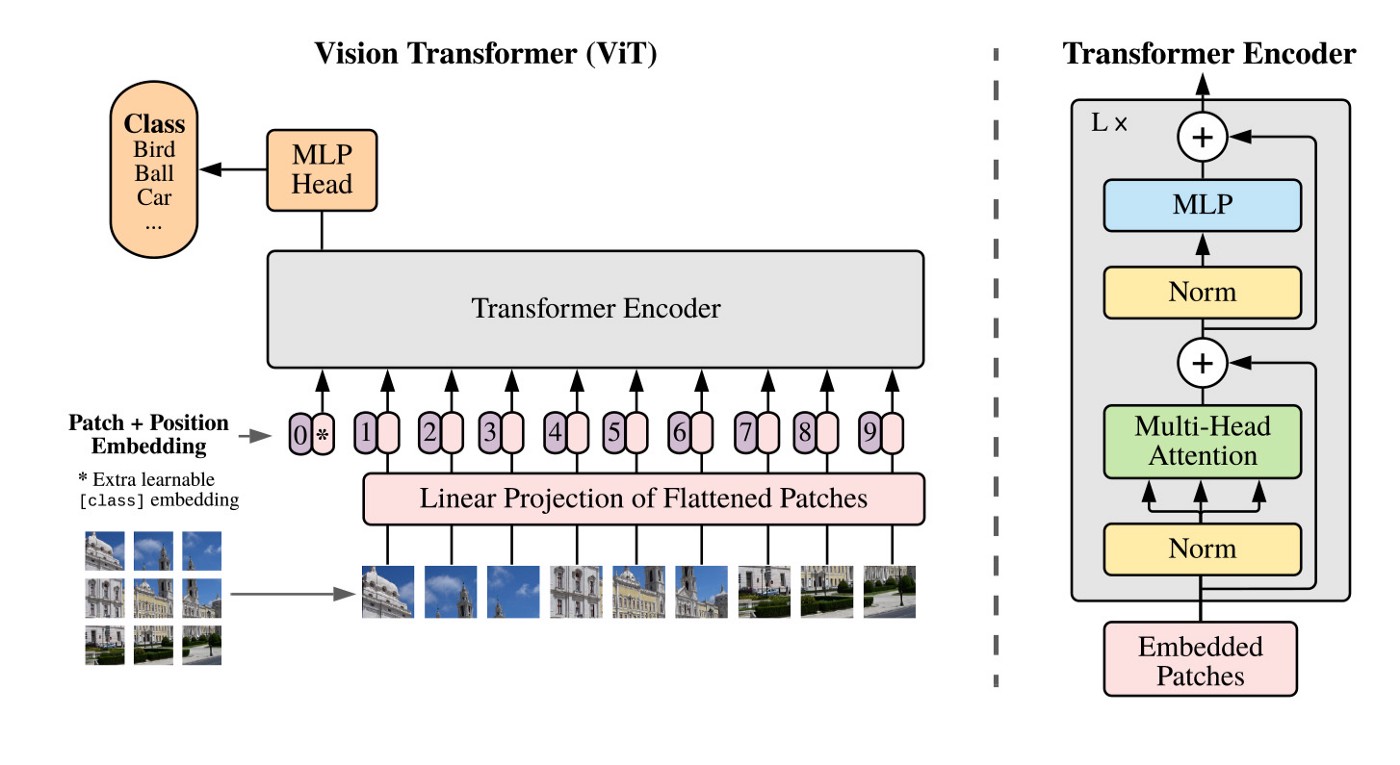
Recent Vision Transformers (ViT) model, adopting Transformer model in NLP, has shown promising results toward generic and scalable architectures for computer vision tasks. This paper study self-supervised ViT model and discuss two emerging properties:
Self-supervised ViT features contain explicit information about semantic segmentation of an image.
Self-supervised ViT features also an excellent k-NN classifiers.
The Vision Transformer treats an image as a sequence of patches, analogous to a series of word embeddings in NLP Transformer model. Figure taken from Nabil’s blog post.
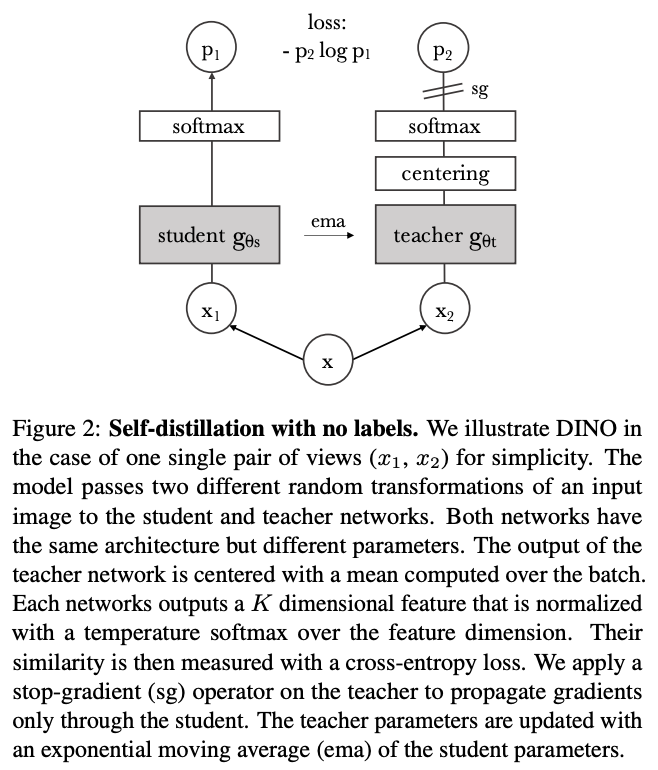
From the findings, the authors develop a self-supervised learning framework called DINO (Knowledge Distilation with no labels). As indicated in the name, the framework uses knowledge distillation strategy to train the model. But instead of using pre-trained model as teacher and running knowledge distillation as post processing step to self-supervised pre-training, the teacher network also performs distillation from student network using self-supervision objective. In other word, both student and teacher network are doing codistillation.
Self-distillation with no labels algorithm. Figure and algorithm snippet are taken from (Caron et al., 2021).
Machine Learning Engineering for Production (MLOps) Specialization [url]
Coursera just launched a new course for building production end-to-end ML systems. Bringing machine learning models to production systems involves many tasks such as discovering data issue and data drift, conducting error analysis, managing computation and scaling. MLOps course discusses how to conceptualize, build, and maintain integrated machine learning systems that continuously operate in production. You will get yourself familiar with the capabilities, challanges, and consequences of machine learning in production.
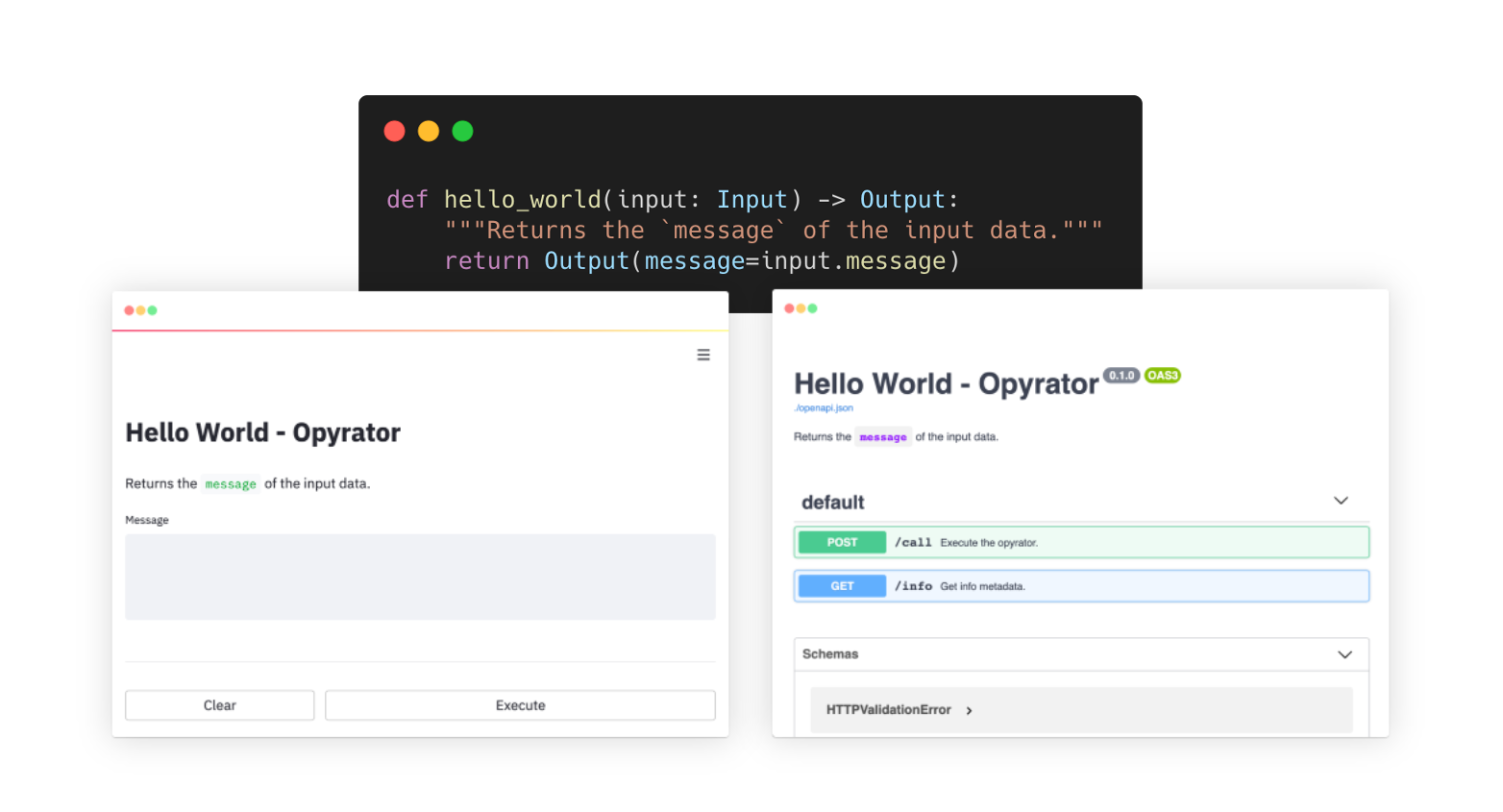
Opyrator: Quickly Turn Machine Learning Codes into Microservices [github]
Figure taken from Opyrator Github Repo.
This open source project combines FastAPI, Streamlit, and pydantic to quickly make your python functions into production-ready microservices. It utilizes FastAPI to automatically generate HTTP API, and Streamlit to automatically generate a web UI. A very useful tool to quickly showcase your machine learning models.
Hello everyone! Starting this week, I am going to summarize my notes in a weekly review post. Here are five machine learning projects / resources / research papers / softwares that I find interesting to explore this week:
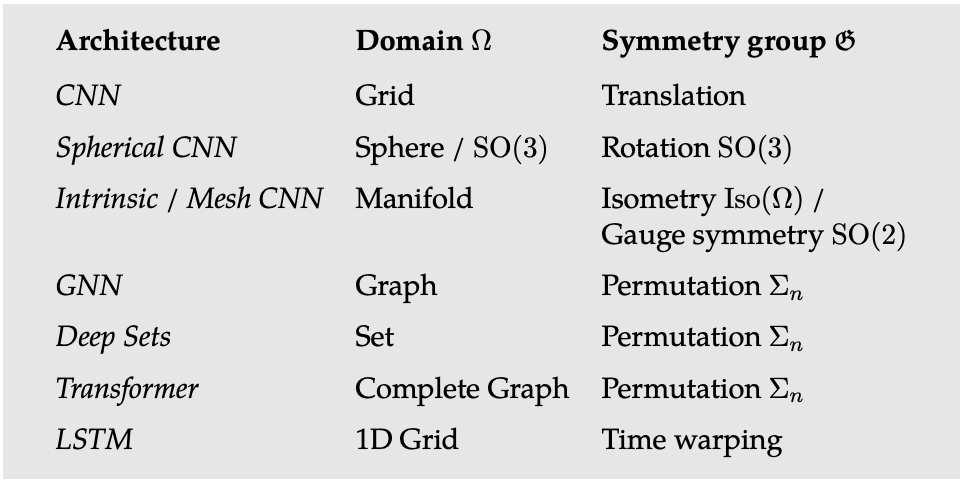
This paper outlines geometric unification of a broad class of machine learning problem, providing a common mathematical framework to derive the most successful neural network architectures such as CNNs, RNNs, GNNs, and Transformers. The work is motivated by Felix Klein’s Erlangen Programme which approaches geometry as the study of invariants.
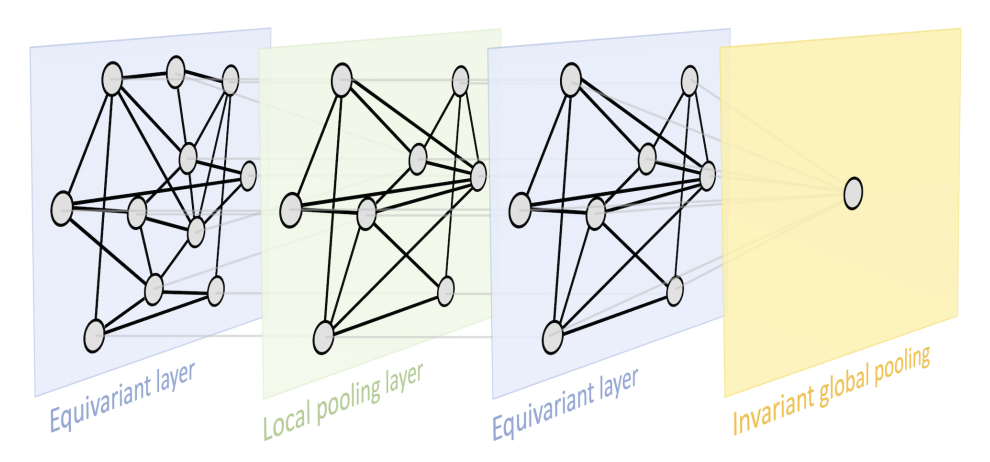
In this light, the authors study symmetries, a certain type of transformation that preserves an object or a structure or a system, and show a general blueprint of Geometric Deep Learning which typically consists of a sequence of equivariant layers, followed by an invariant global polling.
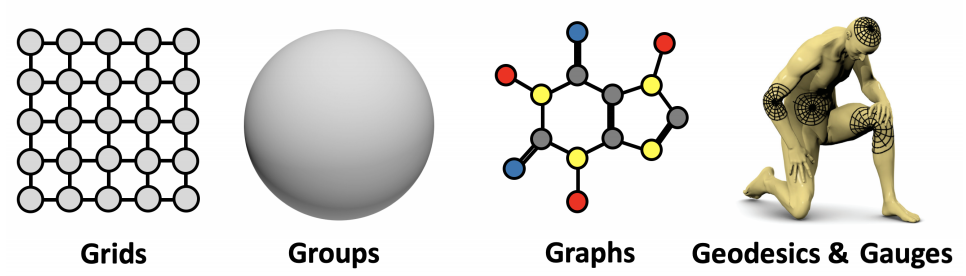
The general blueprint can be applied to different types of geometric domains such grids, groups (global symmetry transformations in homogeneous space), graphs, geodesics (metric structures on manifolds), and gauges (local reference frames defined on tangent and vector bundles).
Jay Alammar creates a cheat sheet for Explainable AI. As more and more machine learning models being deployed in mission critical and high-stake applications such as medical diagnosis, it is important to ensure that the models make decision for the right reason. Jay categorizes explainable AI into five key categories:
Interpretable models by design such as KNN, linear models, logistic regression
Model agnostic methods, for example: SHAP, LIME, and pertubation
Model specific methods, for example: using attention, gradient saliency, and integrated gradients
Example based methods (to uncover insight about a model) using adversarial examples, counterfactual explanations, and influence functions.
This MOOC is developed by scikit-learn core developers. It offers an in-depth introduction to predictive modeling using scikit-learn. The course covers the whole pipeline of predictive modeling including data exploration, modeling (using linear model, decision tree, and ensemble models), hyperparameters tuning, and model evaluation. Highly recommended for beginners!
MixingBoard from Microsoft Research [paper][github]
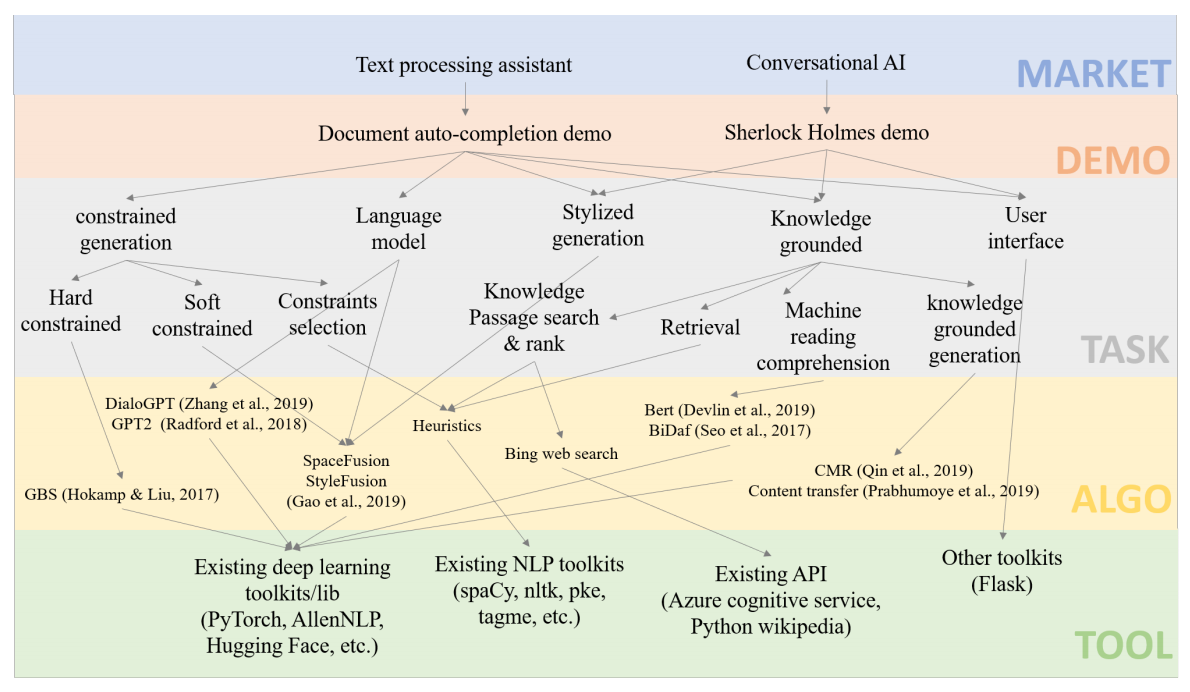
MixingBoard is an open-source platform for quickly building knowledge grounded stylized text generation demos, unifying text generation algorithms in a shared codebase. It also provides CLI, web, and RESTful API interface. The platform has several modules to build a text processing assistant and conversational AI demos. Each module tackles a specific task needed to build the demos such as conditioned text generation, stylized generation, knowledge grounded generation, and constrained generation.
GPT2, DialoGPT, and SpaceFusion can be utilized for conditioned text generation. StyleFusion enables stylized generation via latent interpolation using soft-edit and soft-retrieval strategy. For knowledge grounded generation, it combines knowledge passage retrieval, machine reading comprehension using BERT, content transfer, and knowledge grounded response generation. Finally, hard or soft constraint can be used for constrained generation during decoding stage to encourage the generated texts contain the desired phrases.
The architecture of MixingBoard, composed of basic tools, algorithms, tasks into integrated demos. Figure taken from (Gao et al., 2021).
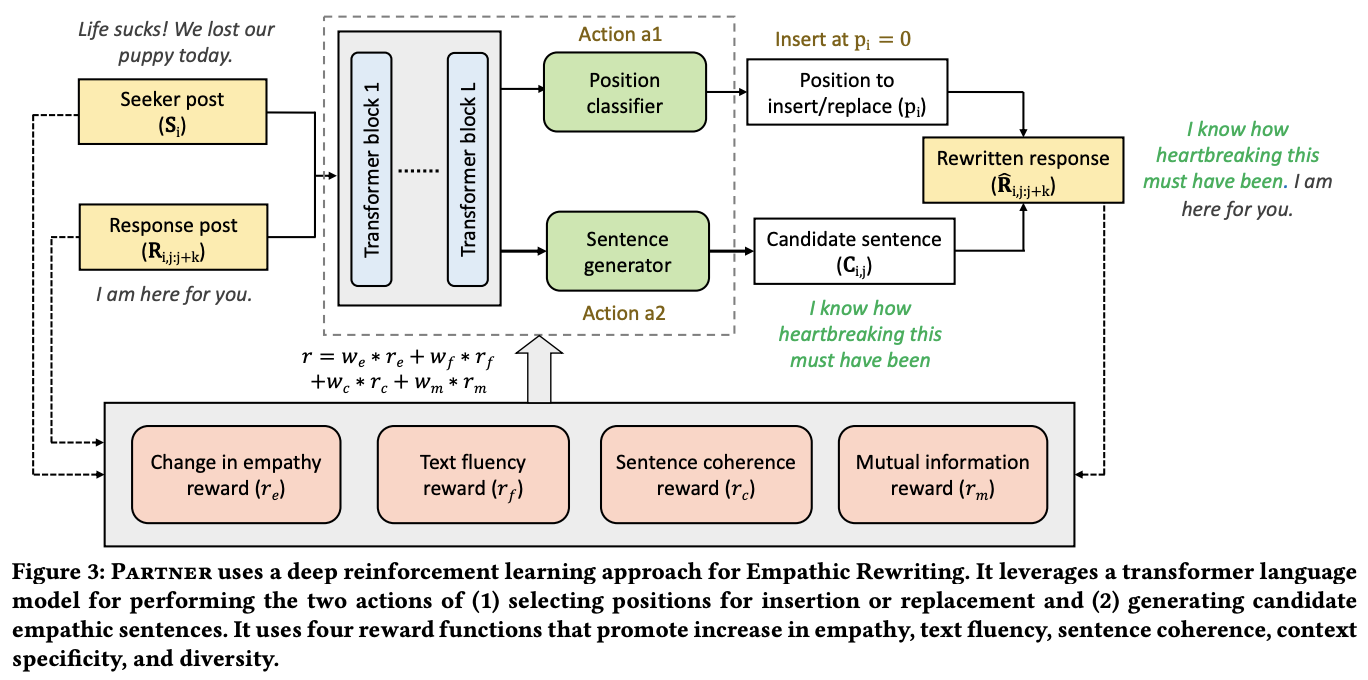
The Web Conference 2021 Best Paper: Towards Facilitating Empathic Conversations in Online Mental Health Support: A Reinforcement Learning Approach. [paper][project page][talk]
The best paper of the Web Conference 2021 addresses an important mental health care. The authors present a great application of text rewriting, transforming low-empathy conversational posts to higher empathy. The task facilitates an empathic conversation which rarely expressed in online mental health support. A reinforcement learning agent, PARTNER, is developed to perform sentence-level edits for more empathic conversational posts.
PARTNER observes seeker and response posts, and performs two actions:
Determine a position in the response span for insertion or replacement.
Generate candidate empathic sentences.
It uses four reward functions aim to increase empathy, maintain text fluency, sentence coherence, context specificity, and diversity.
PARTNER: a deep reinforcement learning agent for empathic rewriting. Figure taken from (Sharma et al., 2021).
About two weeks ago, I spent my time in Jakarta attending Southeast Asia Machine Learning School (SEAMLS) 2019. SEAMLS is a five-days event to learn the current state of the art in machine learning and deep learning. It aims to inspire, encourage, and educate more machine learning engineers, researchers, and data scientists within the Southeast Asia region. I am very fortunate to get selected from about 1,200 applicants. In this post, I will share few things I learned and caught my attention on each lecture.
The first lecture focuses on the math foundation covering linear algebra, analytics geometry, matrix decomposition, vector calculus, probability and distribution, as well as continuous optimization.
I recommend Cheng Soon’s book to learn more details on math foundation in machine learning: https://mml-book.com/.
Lee Wee Sun delivers two lectures: introduction to machine learning [slides], and machine learning basics [slides]. In his first lecture, he briefly explains common machine learning problems: supervised learning, unsupervised learning, and reinforcement learning. He also presents some examples of machine learning tasks such as classification and regression, data compression, and generative models.
In his second lecture, he talks about the basic and fundamental concepts of machine learning:
loss function: we use loss function to help measure our success.
Common loss function: 0-1 loss, square loss, and absolute loss.
Empirical risk minimization
Overfitting
Regularization
I.I.D Assumption
Maximum likelihood
Maximum likelihood and minimizing empirical risk. For some distributions D, maximizing the log likelihood is equivalent to empirical risk minimization with appropriate loss functions.
Maximum a posteriori (MAP) estimation
Bayes estimation
Unsupervised learning: density estimation, mixture model, autoregressive model
feature transformation and normalization: centering, unit range, standardization, clipping, sigmoidal transformation, logarithmic transformation, TF-IDF transformation
dimension reduction: autoencoder, PCA
Some materials in his lecture are taken from few chapters in Understanding Machine Learning: From Theory to Algorithms by Shai Shalev-Shwartz and Shai Ben-David. I encourage you to read the book to understand fundamental theory underlying machine learning principles. The book is available here (free for personal use only).
Practical session on Tensorflow and Google Colab by Subhodeep Moitra.
We have a practical session on the first day of SEAMLS. In this sesion, I learned about Seedbank, a cool website hosting a collection of interactive machine learning examples.
Neural network basics (+tricks of the trade) by Chris Dyer [slides].
Chris begins his talk with examples of neural network applications, followed by explanations on why we favor neural networks.
He explains the details of feed-forward networks, bias and variance in neural networks, differentiable losses, learning optimization, minibatching, and implementation details. He also go through the details on computing derivatives including numeric differentiation (ND), symbolic differentiation (SD), and automatic differentiation (AD).
Second part of Chris’ talk is about tricks of the trade on working with neural networks. Neural network is powerful, but we have a lot of things to be tuned. He gives a general advice:
Make sure you can overfit on a few examples
Try to get a model that overfits on the training data (i.e. reduce bias)
Then try to improve the overfit model (i.e. reduce the variance)
Texts in blue: control bias. Texts in red: control variance. Texts in black: control both bias and variance. Texts in bold face discussed in-depth by Chris.
Optimization in neural network is hard because no guarantee about convergence in neural networks. But, we have few tricks:
Make sure inputs and weights are statistically well-behaved. Input normalization allows you to use larger learning rates. Carefully scaling the variance during weight initialization can significantly help with learning.
Use large numbers of parameters
Use better optimizers
Smarter update rules: momentum, RMSProp, Adam
Better internal representation
Dropout
Batch and layer normalization
One interesting research question he asked during the talk: Does dropout increase or decrease interpretability?
Day 3:
All talks on the third day are related to natural language processing.
In this talk, Vivian explains the basic of word representation, word embeddings, and recurrent neural networks. In word representation, we want to capture the meaning of a word. There are two types of representations being used to represent meaning of a word. First type is knowledge-based representation such as wordnet. However, this approach requires laborious annotation effort, the annotation can be subjective, and newly-invented words need to be manually added to the knowledge-based. It is also difficult to compute word similarity in the knowledge base. Second type of representation leverages on available corpus (thus, it is called corpus-based representation). The representation can be atomic using one-hot representation or neighbor-based using SVD or word embeddings.
For word embeddings part, she explains more details on skip gram model, CBOW, and GloVe, as well as the evaluation of word embeddings.
In the last part of her talk, Vivian discuses about recurrent neural networks, LSTM, GRU, bidirectional RNN, and sequence prediction applications.
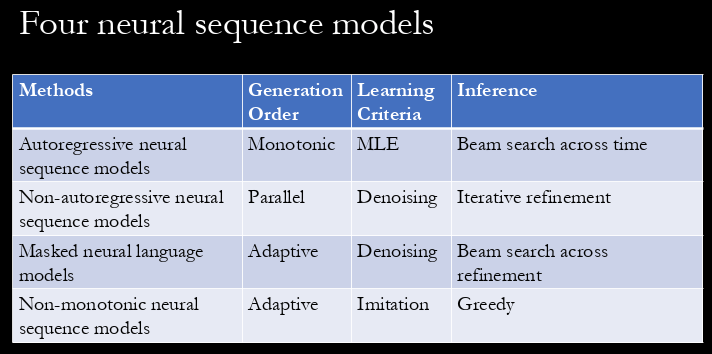
I learned new types neural sequence generation beside the traditional unbounded autoregressive model. Kyunghyun introduces two models: iterative parallel decoding, and non-monotonic sequential generation. In iterative parallel decoding, the idea is that the decoder iteratively refine generated sequence (in denoising fashion). Tokens are generated in parallel instead of a word at a time in this framework.
In non-monotonic sequential generation framework, we don’t assume a pre-specified generation order (such as left to right in standard monotonic sequential generation). In this framework, a word is generated at an arbitrary position, then recursively generating its left and right following a binary tree.
Learned very interesting neural sequence generation approaches today at #SeaMLSchool2019: iterative parallel decoding, and non-monotonic sequence generation. Thanks @kchonyc! pic.twitter.com/QQGOoeujFe
Douwe gives an interesting talk discussing the meaning of multi-modal, multi-modal representation learning, multi-modal fusion, joint embedding spaces, and fusion by attention.
He also presents some applications on multi-modal machine learning: image captioning, visual question answering (VQA), visual reasoning, visual dialogue, and embodied QA.
In this practical session, Mike leads us to build a VGG-like convnet.
Day 5:
Deep probabilistic graphical models by Hung Bui [slides].
Hung gives a nice introduction to deep probabilistic graphical models. I suggest you to go through his slides if you are interested in this topics. He explains latent variable models, probabilistic graphical models, and their relation to deep probabilistic graphical models. He also covers training a deep probabilistic graphical model via variational inference, and reparameterization trick. At the end of his talk, he touches a bit on representation learning with deep probabilistic graphical models.
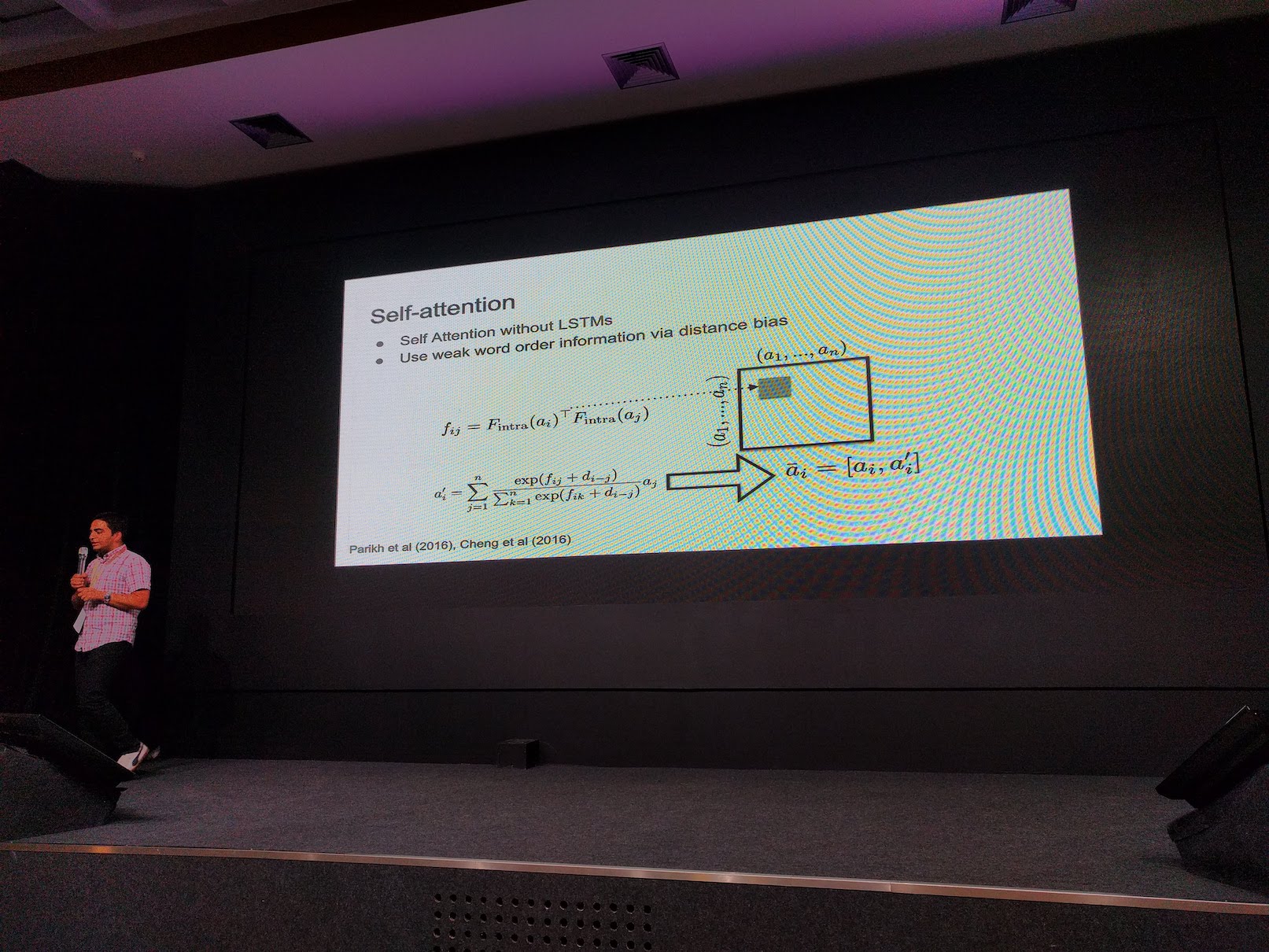
Manaal introduces the basic of attention mechanism, then followed by self-attention, transformer architecture, and BERT. He also touches a bit on the interpretability of attention.
In the final lecture in SEAMLS, Truyen shows many applications of machine learning techniques in biomedicine domain. He presents various problems and applications on set, sequence, and graph data in biomedicine.
Beside lectures, there are three panel discussions and poster sessions. Overall, this event is well-organized, and I really like the program. The program covers good balance of fundamental and more advanced topics. Full programs are available here, along with the slides material. I highly recommend you to go through the slides material on topics you want to learn.
2018 has been an exciting year for me. I encounter, explore and learn many exciting ideas and efforts in NLP. In this post, I briefly summarize NLP developments and efforts that excite me in 2018.
1. Translation without Parallel Data
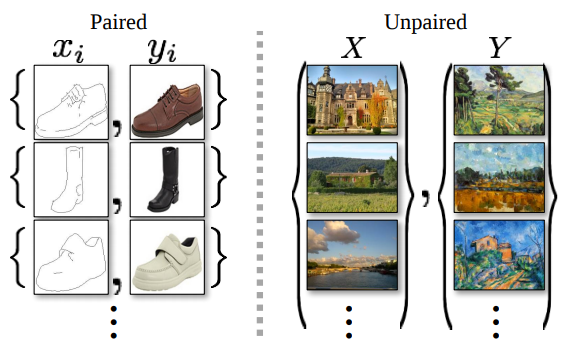
Recent successes in unpaired image-to-image translation such as DiscoGAN , and CycleGAN inspire work on similar goal in NLP, more specifically in the area of machine translation and text generation. In unpaired translation setting, we eliminate the need of building parallel corpora which is very tedious and slow process.
Difference between paired and unpaired training data. Each example is a correspondence between xi and yi in paired training data, whereas the correspondence information is not available in unpaired training data. Figure taken from (Zhu et al., 2017).
When dealing with unpaired translation setting, a machine learning model needs to discover cross-domain alignment without supervision. In the absence of correspondence mapping information, one trick that has been shown to be effective is utilizing back-translation. In back-translation, after we translate from source to target, we translate the target back to the source. Many models utilize this back-translated source as reference to guide the translation quality.
Learning from unpaired training data is perfect fit for unsupervised machine translation system where we only have access to monolingual corpora. Recent works by (Lample et al., 2018a; Lample et al., 2018b) show that good initialization, language modeling, and back-translation are three principles for success in building unsupervised machine translation model.
Three principles of unsupervised machine translation. Figure taken from (Lample et al., 2018b).
Beside language translation, this approach has been used in many text generation problem such as author attribute anonymity (Shetty et al., 2018), text generation with attribute control (Logeswaran et al., 2018), and text style transfer (Zhang et al., 2018).
2. Text Style Transfer
Example of neural style transfer for image. Figure taken from (Jing et al., 2018)
Motivated by growing interest in Neural Style Transfer in computer vision (see review by Jing et al., 2018), there are a number of recent work on style transfer for text generation. Text style transfer aims to rewrite a given text in a different linguistic style, while at the same time preserving the content of original text.
Many works on text style transfer formulate the problem by learning disentangled latent representation (Bengio et al., 2014) from input text, producing a latent representation consists of content and style component. Using this representation, one can easily control and modify the style component, while keeping the content representation intact, to generate output text. We hope that the generated output has the same content, but in different style.
Disentangling content and style representation. Figure taken from (Shen et al., 2017) slides.
Despite many work on text style transfer, a fundamental question still remains: what constitutes a style? Is sentence modification a good example of text style transfer? Tikhonov and Yamshchikov (2018) suggest that style has to be orthogonal to semantics, and thus any semantically relevant information could be expressed in any style. Furthermore, evaluation on generated text also remains a big question. How do we accurately measure the style, while at the same time ensure the meaning is preserved? Current evaluations are mainly based on style classifier accuracy and human evaluation. Pang and Gimpel (2018) suggest that style classifier accuracy alone it not sufficient to evaluate text style transfer, and propose to combine style classifier accuracy with semantic similarity and fluency metrics to better assess non-parallel textual transfer.
3. Deep Contextual Representations
Word embedding has been an important building block of many deep learning models for NLP tasks. Word embedding encodes information from each word in input text to be processed by deep learning models. Many methods such as word2vec and glove, have been developed to generate word embedding that captures linguistic contexts of words. Recent work on word embedding involves refining (retrofit) learned word embedding to external information such as semantic lexicons (Faruqui et al., 2015) and knowledge graph (Lengerich et al., 2018).
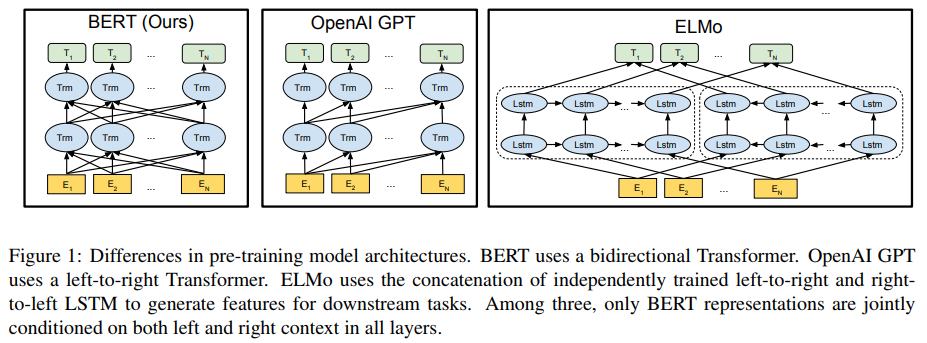
Traditionally, word embedding vectors are pre-trained using shallow neural network on language modeling task. Using large general purpose corpora such as wikipedia or Google news, one can learn good embedding vectors to be used for many NLP tasks. In 2018, we see more efforts in exploiting contextual information in deep neural network, and thus the word representations are derived from multiple layer in deep networks. OpenAi GPT (Radford et al., 2018), ELMo (Peters et al., 2018), and BERT (Devlin et al., 2018) show deep contextual representations give large improvement on broad range of NLP tasks.
BERT, OpenAI GPT, and ELMo architectures. Figure taken from (Devlin et al., 2018)
4. Information Extraction for Scientific Literature
With constant increase of scientific papers being published every day, there are growing needs of a scientific knowledge discovery tool. Information extraction from scientific papers becomes an important application of natural language technology. Meta, a scientific discovery tool for biomedical research, extracts various medical concepts, and makes them available to search and follow. Allen AI team behind SemanticScholar develops a scalable system to construct literature graph in order to facilitate algoritmic discovery in the scientific literature (Ammar et al., 2018). SemEval 2018 also has one track for this task. SciIE (Luan et al., 2018) employs multitask approach for identifying entities, relations, and coreference in scientific papers.
In the area of social science, NYU Coleridge Initiative hosts Rich Context Competition which aims to automatically discover research datasets, methods, and fields in social science research publications. The competition finalists (from GESIS, KAIST, Paderborn University, and Allen AI) will be presenting their work in Rich Context Competition Workshop on 15 February 2019. They will webcast the workshop. Register here! 🙂
We see the birth of more and more datasets for more specific and challenging NLP tasks in 2018. 15 new datasets were presented in EMNLP 2018 alone (Sebastian Ruder summarizes them in his EMNLP 2018 highlight). There are also NLP benchmarks based on established datasets for studying and evaluating NLP models:
GLUE benchmark (Wang et al., 2018): a benchmark consists of nine sentence- and sentence-pair language understanding tasks, i.e. CoLA, SST-2, MRPC, STS-B, QQP, MNLI, QNLI, RTE, and WNLI.
decaNLP (McCann et al., 2018): a benchmark for a multitask NLP challenge consisting of question answering, machine translation, summarization, natural language inference, sentiment analysis, semantic role labeling, relation extraction, goal-oriented dialogue, semantic parsing, and commonsense reasoning.
More and more datasets will definitely trigger rapid NLP advancement in solving various NLP tasks. A nice crowdsourcing effort led by Sebastian Ruder to track NLP progress can be seen at nlpprogress.com.
There are some great AI 2018 roundups from various blog posts which inspire me to write this blog post. I highly recommend you to read these posts:
Living Analytics Research Centre (LARC) and Elastic gave a workshop titled Elasticsearch: You know, for search! and more! at FOSSASIA 2016 last week. It’s an introduction to Elasticsearch, and we shared our experience in using Elasticsearch at LARC. The crowd was great, and we had a bunch of questions related to Elasticsearch, and particularly how we utilize Elaticsearch in our lab. Here is our slide deck:
And here is the slide deck from Elastic (by @medcl):