Hello, my machine learning reading this week focuses on alternative architectures to self-attention in Transformer. In particular, I read three papers: FNet, gMLP, and Attention-free Transformer (AFT). Let’s see the main ideas in these papers.
FNet: Mixing Tokens with Fourier Transforms [paper]
Self-attention mechanism in Transformer architecture serves as an inductive bias, connecting each token in the input with weights to every other tokens. This mechanism has shown very effective and achieved many state of the art results in many NLP tasks. However, the standard self-attention mechanism requires quadratic time and memory with respect to sequence length, limiting its applicability to long sequences. There are several effort to reduce this quadratic complexity by sparsifying or compressing the attention matrix (see Tay et al., 2020 on Efficient Transformer survey).
This paper proposes a different approach, replacing self-attention sublayer in transformer architecture with Fourier transform. Fourier transform can be computed fast on GPUs and TPUs, and it does not carry any learned weight, making it smaller than standard Transformer. Thus, the architecture, namely FNet, is faster and using less memory than standard Transformer. FNet is capable to handle long sequences.
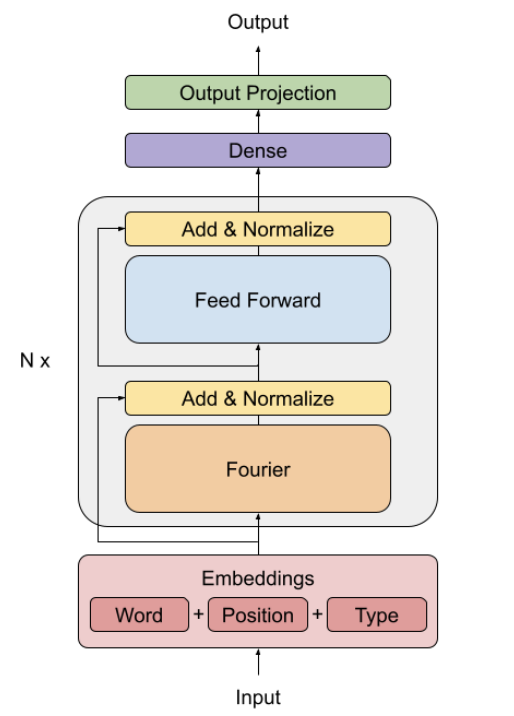
The authors also have another model (called linear encoder), replacing self-attention sublayer with two linear sublayers. It is originally introduced as a baseline to the FNet, but it surprisingly turns out that the linear encoder also performs very well too. They also experiment with hybrid FNet attention model by replacing final two Fourier sublayers of FNet with self-attention sublayers. The hybrid model increases the performance of the base FNet model with small additional training cost. The improvement indicates that self-attention is important, but we do not need a big self-attention sublayers to archive strong performance. Here is a great YouTube video explaining FNet by Yannic Kilcher.
Pay Attention to MLPs [paper]
gMLP is another approach to replace Transformer using MLP layers with gating. gMLP consists of channel projection and spatial projection with multiplicative gating. This alternative is simpler and cheaper to compute than self-attention layer in Transformer.
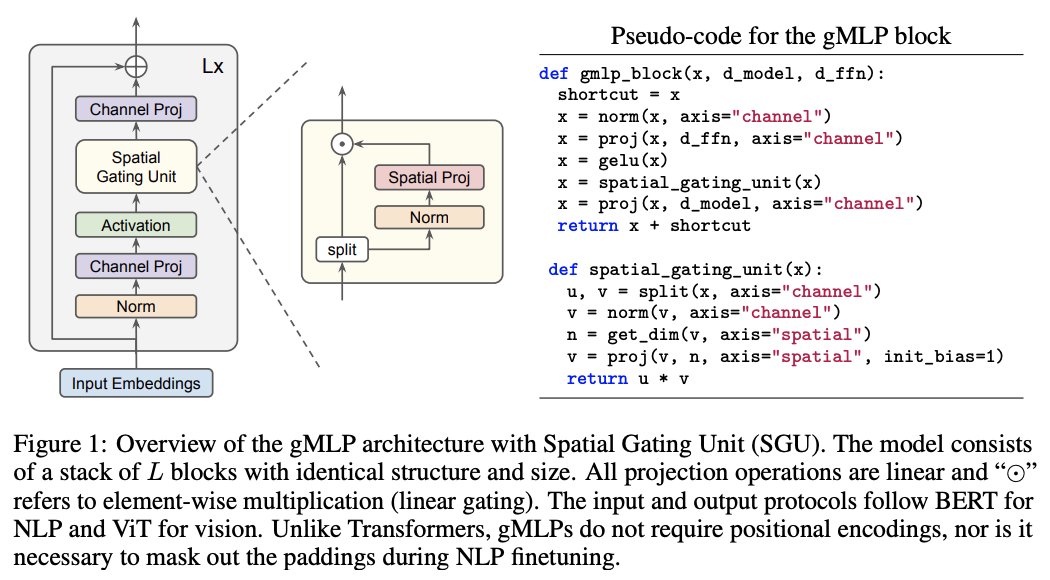
The main component of gMLP is spatial gating unit which captures spatial interaction, offering an alternative mechanism to capture high-order relationships. The authors of this paper perform several experiments comparing gMLP with Vision Transformer (ViT), DeIT (ViT with improved regularization), and BERT. They also study the importance of gating in gMLP, the scaling properties of gMLP, and the usefulness of adding tiny self-attention in gMLP. Attaching a tiny single-head self-attention to the gating function of gMLP improves gMLP to outperform Transformer of similar capacity.

Attention-Free Transformer [paper]
This paper replaces standard multi-head attention in Transformer with more efficient element-wise operation between query and combined key and value. This replacement improves the computation to linear time and space complexity with respect to input and model size. Attention-Free Transformer (AFT) performs weighted average of values (V) combined with the keys (K) and a set of learned pairwise position biases.
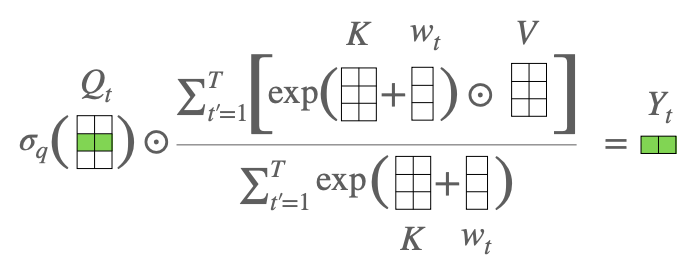
These few papers show recent developments to improve the efficiency of Transformer models by modifying or replacing the most expensive component in Transformer: self-attention layer.
That’s all for this week. Enjoy and see you next week!