This week, I read a paper on pre-processing training data for Language models. Here is a short summary.
Deduplicating Training Data Makes Language Models Better [paper][github]
This paper shows that datasets for language modeling contain many long repetitive substrings and near-duplicate examples, for example a single 61-word sentence repeated over 60,000 times in C4 dataset. To address this issue, the authors of this paper propose two scalable deduplication methods to detect and remove duplicate sequences.
The advantages of training a language model on deduplicated datasets are as follow:
- Reducing the rate of emitting memorized training data.
- Removing train-test overlap that is common in non-deduplicated datasets. Train-test overlap causes model overfitting.
- More efficient model training due to smaller datasets.
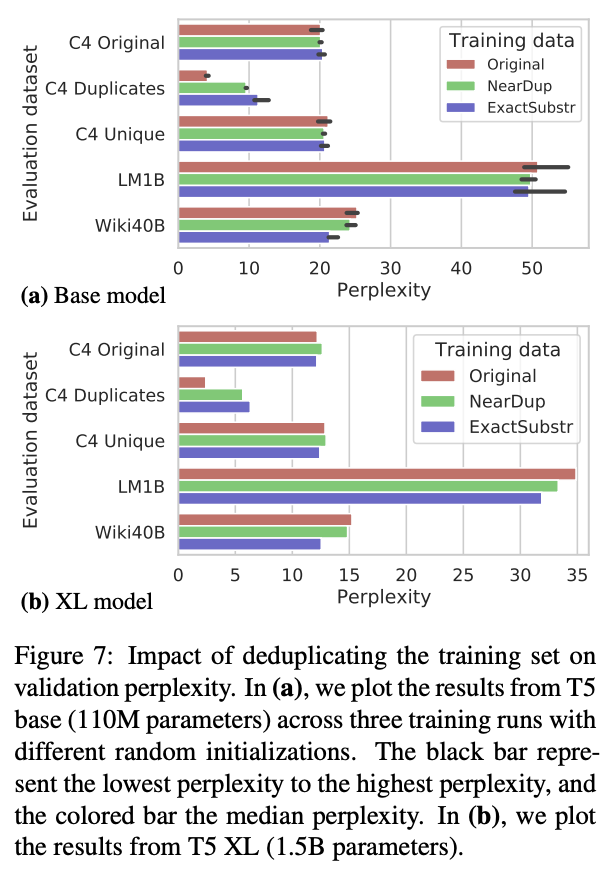
- Deduplicating training data does not hurt perplexity.
Naive method to perform deduplication using exact string matching on all example pairs is not scalable. Two deduplication methods are introduced in this paper:
- Removing exact substring duplication using suffix array (ExactSubstr)
- Approximate matching with MinHash (NearDup)
More details on each method can be read in the paper. The authors also release the source codes.
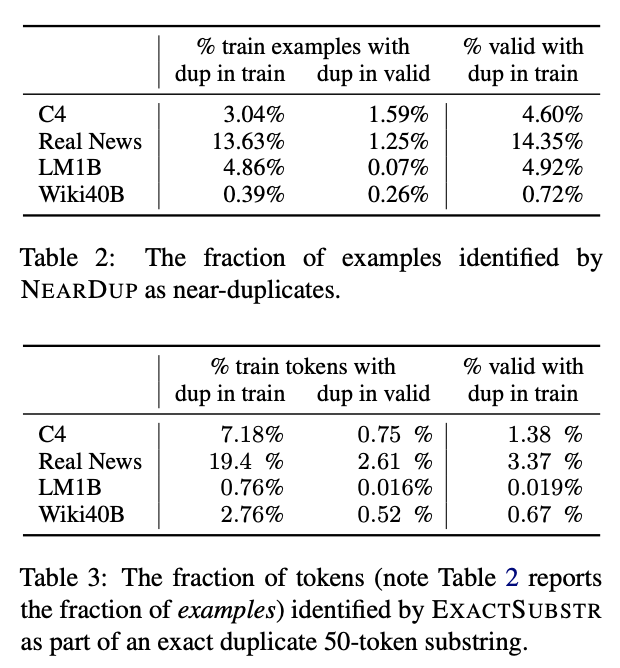
Below are the percentage of duplicate examples in standard LM datasets detected by ExactSubstr and NearDup methods, as well as the impact of deduplicating training set on validation perplexity.
See you next week.