This week in machine learning is filled with GAN-related papers from Nvidia. DatasetGAN shows the usefulness of GAN (Generative Adversarial Network) in generating simulated training data at scale. Another paper from Nvidia shows a nice GAN application for controllable 3D rendering from a single 2D image. Let’s take a look at the idea on each paper.
DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort [website][paper]
The availability of labeled data is one big bottleneck to have an effective machine learning system. There are huge amount of unlabeled data out there, but high-quality labeled datasets are still limited because it takes huge amount of time, human resources, and money to create such datasets.
DatasetGAN is simple semi-supervised approach to synthesize massive large high-quality dataset with minimal human annotation. It shows that we can synthesize high-quality semantically segmented images using GAN, utilizing semantic knowledge (such as viewpoint, object identity) in its high dimensional latent space.

DatasetGAN uses StyleGAN as the rendering engine, and then adding style-interpreter component to synthesize labels from StyleGAN latent vectors. Style interpreter consists of an ensemble of MLP classifiers to predict the label on each pixel based on the features from the upsampled StyleGAN latent vectors.
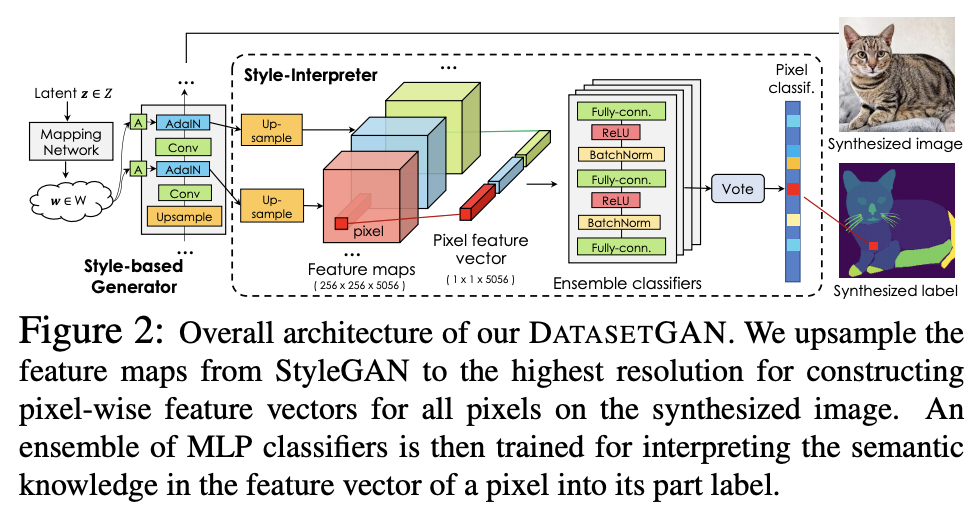
The authors perform experiments on bedrooms, cars, heads, birds, and cats images for semantic segmentation, and keypoint detection. They also showcase an application of this approach to perform animatable 3D object reconstruction from an image.
Image GANs Meet Differentiable Rendering for Inverse Graphics and Interpretable 3D Neural Rendering [paper][blog]
This paper reconstructs 3D objects from 2D images, often known as inverse graphics task. Most of existing approaches rely on the availability 3D labels to train a model. The authors of this paper present a way to extracts and disentangle 3D knowledge learned from GAN using differentiable rendering. Using this approach, they are able to obtain high-quality 3D rendering with low annotation effort.
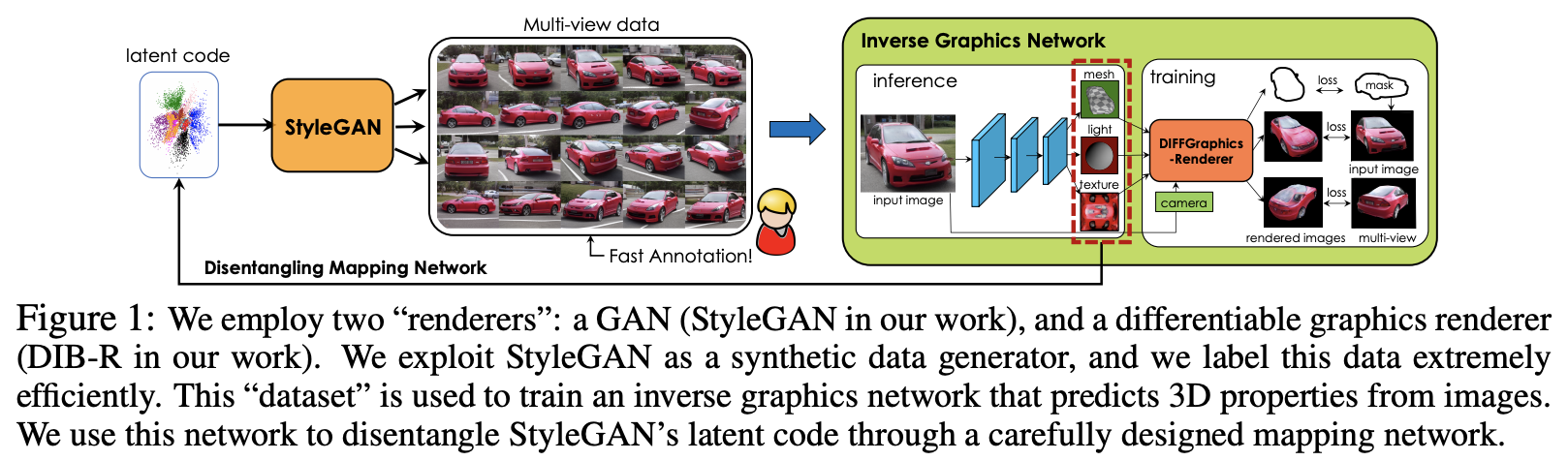
The approach aims to disentangle camera viewpoints, shapes, texture, light, and background. It combines two state-of-the art renderer as main components. In the first component, they utilize StyleGAN as multi-view data generator. Each layer in StyleGAN controls different image attribute, for example early layers control viewpoint, while intermediate and high layers control shape, texture, and background. They leverage on this knowledge, and uses first four layers of StyleGAN to disentangle camera viewpoints.
The second component is inverse graphics neural network DIB-R (Chen et al., 2019) to predict 3D shapes and texture from an image. This model enables them to detect 3D properties from image. This 3D properties are then mapped back into StyleGAN latent vectors, allowing them to control the StyleGAN rendering based on certain properties.
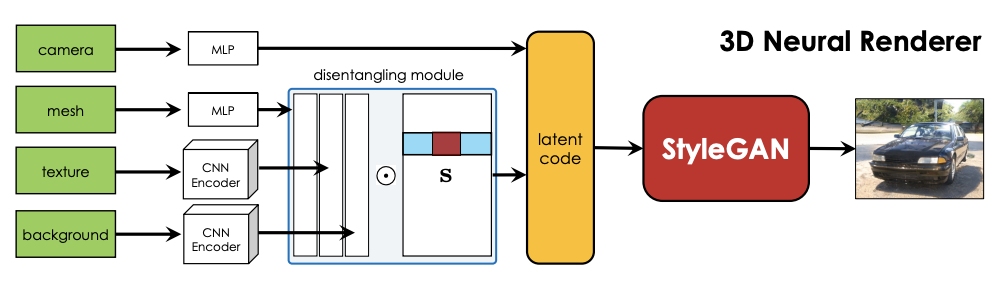
The model is still unable to predict correct lighting, and disentangling background is still a challenge. Moreover, predicting shapes of out-of-distribution objects (such as Batmobile and Flintstone car) is also another significant challenge.
That’s all for this week. Stay safe, and see you next week!