My machine learning this week is about a long text generation. I also encounter an open source computer vision framework for self-supervised learning, and a resource on reproducible machine learning course. Let’s take a look.
Progressive Generation of Long Text with Pretrained Language Models [paper][github]
When generating long text, current large-scale fine-tuned pretrained language model exhibits some issues such as excessive repetitiveness or incoherence between sentences that are far apart. Another strategy for long text generation is using content planning before the actual text generation. The content planning in this strategy may require another task such as summarization or semantic role labeling which demands another resources and labeled data. Another more recent non-monotonic generation approaches also require specialized architectures, making them hard to integrate with the existing pretrained language models.
This paper proposes a simple strategy for long text generation (~1000 tokens) which can still leverage on the existing pretrained models. The main idea is to progressively generate text in multiple stages, breaking the complex text generation into multiple easier steps, from a skeleton to a full passage. Each stage refines the output from the previous stage by adding finer details. The algorithm is called Progressive Generation (ProGen).
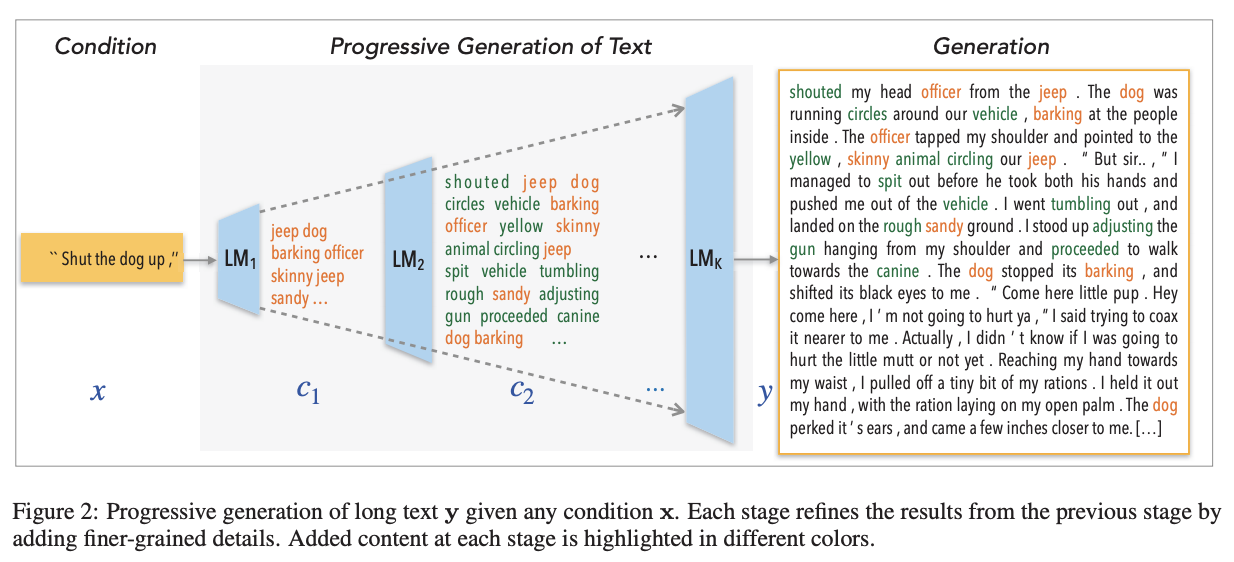
To achieve this mechanism, ProGen uses limited vocabularies on earlier stages based on the word importance, for example the first stage only uses 15% of the most important words in the corpus, the second stage only uses 20% of the most important words in the corpus, and so on. Then, the training data for each stage can be easily constructed by dropping all tokens that do not belong to the vocabularies in the particular stage. We can add noises to improve robustness and reducing data bias. Finally, we fine-tune a pretrain language model on each stage.

We can see that ProGen is conceptually very similar to non-monotonic generation. But, the generation is still performed in autoregressive, left-to-right fashion, making it more compatible with the existing pretrained language models. Compare to content planning strategy, ProGen has more flexible intermediate stages. Typical content planning strategies only have two stages.

Lightly [github]
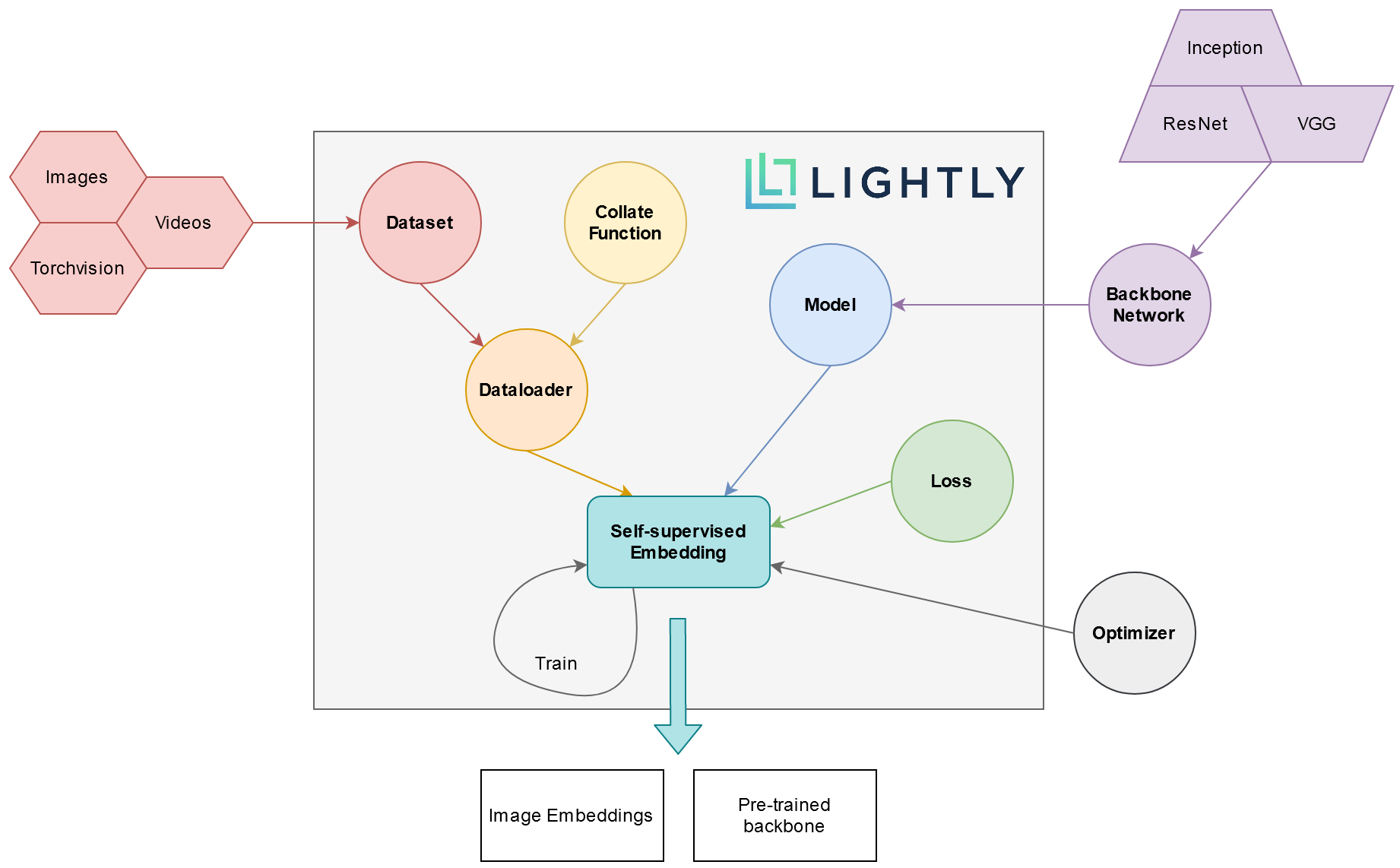
Lightly is computer vision framework for self-supervised learning. This framework helps us to curate our dataset better, find edge cases, and improve data quality. The framework supports several models such as MoCo, SimCLR, SimSiam, BarlowTwins, BYOL, and NNCLR.
Reproducible Deep Learning Course [website]
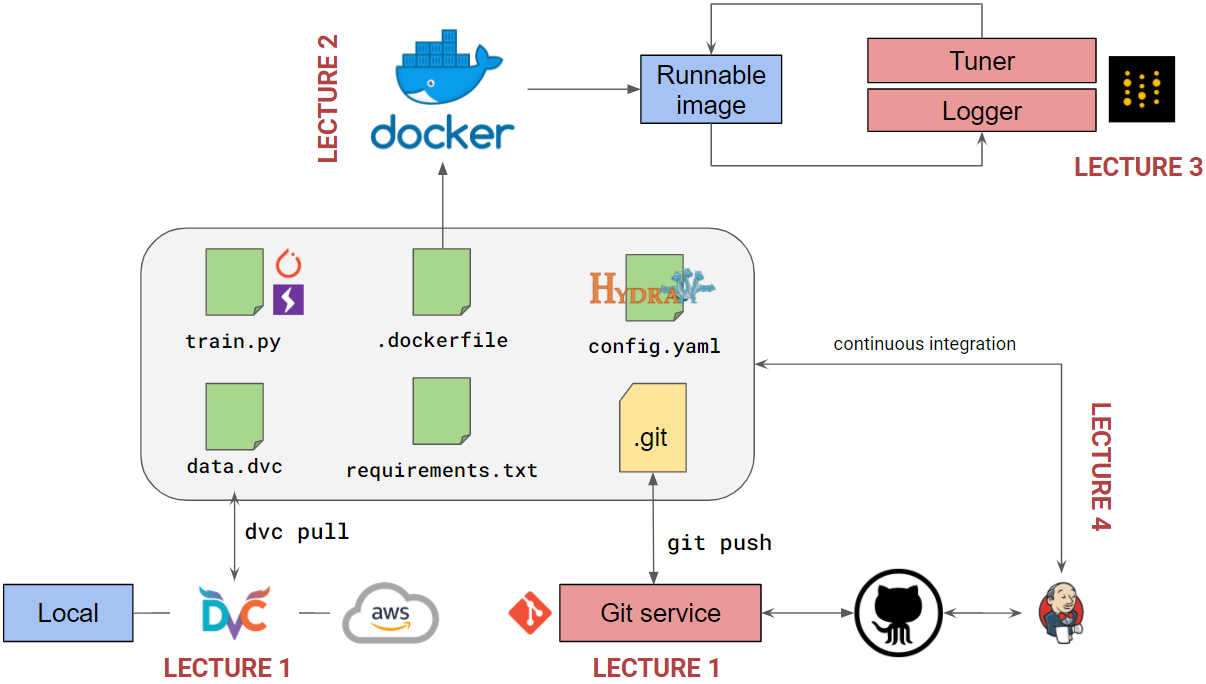
I stumble upon a great resource on a practical reproducible deep learning course by Simone Scardapane. The course content covers tools that you need for reproducible deep learning workflow such as git, hydra, data version control, docker, weight & biases, and continuous integration. Great course by Simone.
That’s all for this week. How’s your machine learning week? Leave a comment below.
Stay safe and see you next week!