This week in machine learning features NAACL 2021 Best short paper which is also related to PET we discuss last week. Let see main ideas for this paper.
How Many Data Points is a Prompt Worth? [paper][blog][github]
The standard approach for transfer learning using pretrained model for classification is to attach a head layer to perform classification, taking in the pretrained representation to predict the output class. The other alternative approach is to use a prompt, reformulating the task into a task-specific string and ask the model to produce a textual output corresponding to a class label. Prompt-based approach provides a more flexible way to inject extra task-specific guidance to fine tune the model. PET (which we discuss last week) has shown that prompt-based effectiveness on low-data regimes.
This NAACL 2021 best short paper presents a very nice analysis comparing head-based and prompt-based, aiming to quantify how many data points is a prompt worth? The author takes a roberta-large and compare the performance using head-based and prompt-based approach across different available data points (starting from 10 data points and increasing exponentially). For the prompt-based approach, they follow PET model (Schick and Schütze, 2021).
Using the both head-based and prompt-based performance curves on all data points, the data point advantage is estimated by first isolate the y-axis band of the lowest accuracy and the highest accuracy where two curves match in accuracy (this is shown in cross-hatch region in the figure below). Then, the area between two linearly-interpolated curve divided by the height of the band represents the number of data point advantage.
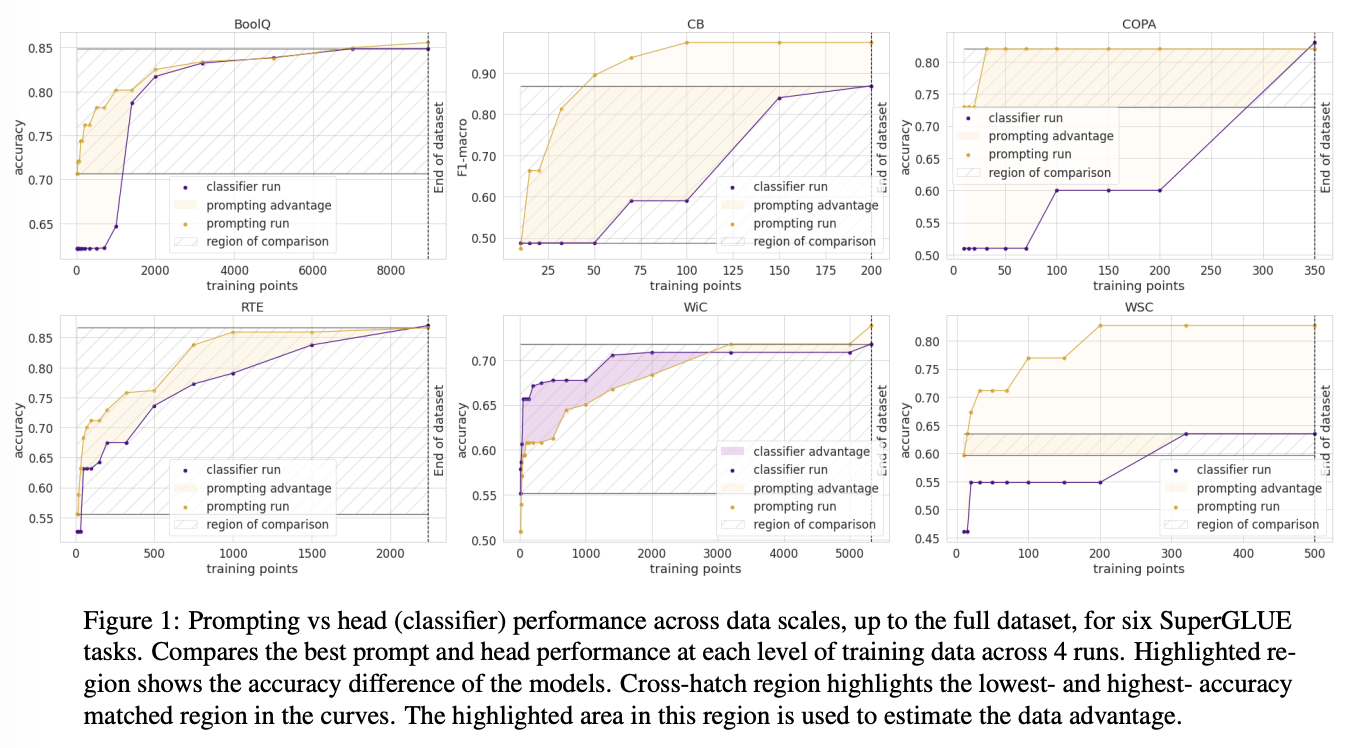
Experiment results on SuperGLUE benchmark shows prompt-based data advantage on all tasks except WiC. Notable data advantage can be seen in low-data regime.
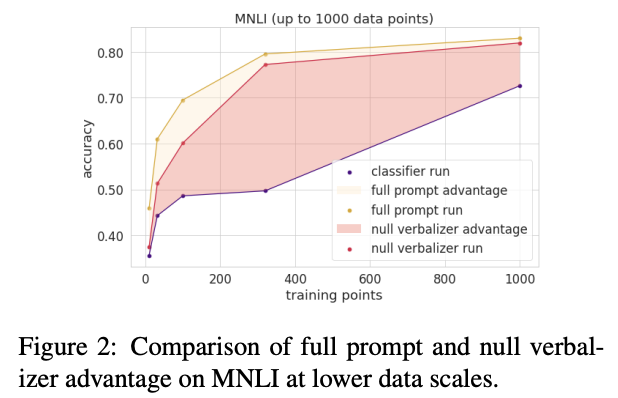
The authors also perform analysis on the impact of verbalizer in prompt-based approach. To do this, they introduce null verbalizer (random first name to replace “yes”, “no”, “maybe”, “right”, “wrong”). They find that verbalizer is important especially when the availability of the training data points is low. Null verbalizer reduces the prompt-based performance in low-data regime. However, with more and more training data, prompt-based model can adapt to null verbalizer.
That’s all for this week. Stay safe and See you next week!