For machine learning week, I study about unsupervised domain adaptation in NLP this week, reading a relevant survey paper in this area. Here are my short summary notes.
A Survey on Neural Unsupervised Domain Adaptation in NLP [paper][github]
In many NLP applications, the availability of the labeled data is very limited. Although deep neural network works well for supervised learning, particularly with pre-trained language model to achieve state-of-the-art performance on NLP tasks, there is still a challenge to learn from unlabeled data under domain shift. In this setting, we have two problems to tackle:
- The target domain and the source domain do not follow the same underlying distribution (Note that the task is the same). For example,
- The source domain is news and wikipedia articles, and the target domain is scientific literatures.
- The more extreme case is cross-lingual adaptation, the source domain is in one language, and the target domain is in another language.
- The scarcity of labeled data in the target domain, and we need unsupervised domain adaptation techniques to handle this issue.
This survey summarizes relevant work on unsupervised domain adaptation where we mitigate the domain shift by learning only from unlabeled target data. The authors also discuss the notion of domain (what constitute a domain?), and suggest to use better term: variety space.
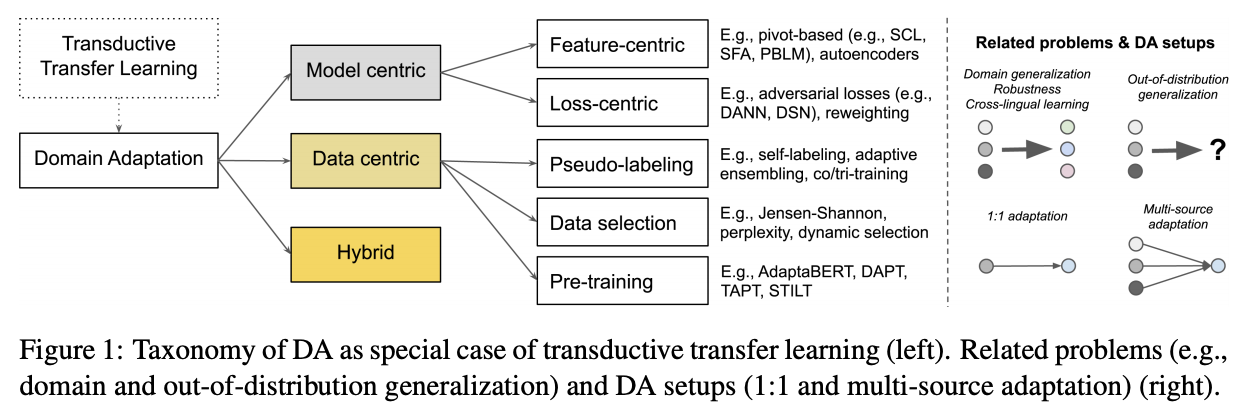
Domain adaptation methods can be categorized into 3 groups of approaches:
- Model-centric approaches: redesign parts of the model by modifying feature space or loss function.
- Feature-centric methods by feature augmentation or feature generalization.
- Feature augmentation methods uses common shared features (called pivots) to construct aligned space, for example structural correspondence learning (SCL), spectral feature alignment (SFA), and pivot-based language model (PBLM).
- Feature generalization utilizes autoencoder to find good latent representation that can be transferred across domains. Stacked denoising autoencoder (SDA), marginalized stacked denoising autoencoder (MSDA) have been used for unsupervised domain adaptation.
- Loss-centric methods to regularize or modify model parameters. It can be divided into two groups: domain adversaries and instance-level reweighting.
- Domain adversaries is probably the most popular methods for neural unsupervised domain adaptation. The idea is inspired by GAN approach which tries to minimize real and synthetic data distribution by learning a representation that cannot be distinguish between real and synthetic data. Bringing that into the domain adaptation setting, cross-domain representation can be achieved, if a domain classifier cannot distinguish whether the input comes from the source or the target domain. A popular Domain adversarial neural network (DANN) uses a gradient reveral layer to achieve cross-domain representation. A more recent approach utilizes Wassertein distance to achieve cross-domain representation.
- The idea of instance-level reweighting methods is to assign a weight on each training instance proportional to its similarity to the target domain.
- Other methods explicity reweight the loss based on domain discrepancy information, such as maximum mean discrepancy (MMD), and kernel mean matching (KMM).
- Feature-centric methods by feature augmentation or feature generalization.
- Data-centric approaches: focuses on getting signal from the data.
- Pseudo-labeling using a trained labels to bootstrap initial ‘pseudo’ gold labels on the unlabeled instances. Pseudo-labeling applies semi-supervised methods such as self-training, co-training, and tri-training.
- Data selection aims to find the best matching data for the new domain using domain similarity measures such as JS divergence or topic distribution.
- Pre-training models leveraging large unlabeled data. Starting from a pre-trained transformer model followed by fine-tuning on small amount of labeled data has become the standard practice in NLP due to high performance on many NLP tasks. In domain adaptation, pre-training can be divided into:
- Pre-training alone
- Adaptive pre-training involving multiple rounds of pre-training
- Multi-phase pre-training: pre-training followed by two or more phases of secondary pre-training, from broad domain to specific domain to task-specific domain, for example: BioBERT, AdaptaBERT, DAPT, TAPT.
- Auxiliary-task pre-training: pre-training followed by multiple stages of auxiliary task pre-training involving intermediate labeled-data tasks.
- Hybrid approaches: intersection between model-centric and data-centric.
One of the authors, Barbara Plank, created a Github repo to collate all relevant papers in this area.
That’s all. Stay safe and see you next week.