Following my study on unsupervised domain adaptation last week, I write a short note on domain divergences survey for this week in machine learning. In domain adaptation, domain divergence measures the distance between the two domains, and reducing the divergence is important to adapt machine learning models to a new target domain.
A Survey and Empirical Analysis on Domain Divergences [paper]
As a measure of the distance between two domains, domain divergence is a major predictor of performance in target domain. Domain divergence measures can be utilized to predict performance drop when a model is applied in a target domain. This paper reviews 12 domain divergence measures, and reports a correlation analysis study on those divergence measures on part-of-speech tagging, named entity recognition, and sentiment analysis on more than 130 domain adaptation scenarios.
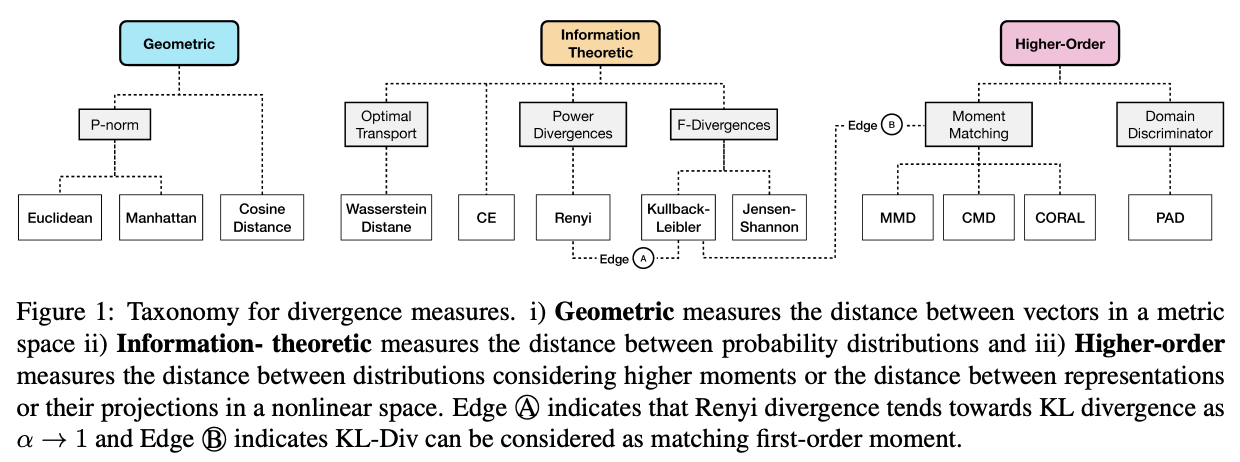
Domain divergence can be categorized into three categories:
- Geometric measures
Geometric measures use vector space distance metric such as Cosine similarity, Manhattan, and Eucledian distance to measure the distance between features extracted from instances from different domains . These measures are easy to compute, but do not work well in a high dimensional space. - Information theoretic
Information theoretic measures capture the distance between probability distributions, for example cross entropy, f-divergences (KL and JS divergence), Renyi divergence, and Wasserstein distance. - Higher-order measures
Higher-order measures consider higher order moment matching of random variables or divergence in a projected space. Maximum Mean Discrepancy (MMD), CMD, and CORAL are measures utilizing higher order moment matching, whereas Proxy-a-distance (PAD) uses a classifier to measure the distance between source and target domain.
Note that KL divergence is related to both Renyi divergence and first-order moment matching.
How do we apply divergence measures?
According to this survey paper, the divergence measures can be applied in three different ways:
- Data selection
One way is to use divergence measures to select a subset of data from source domain that share similar characteristics to the target domain. For example, using cosine similarity or JS divergence to select data for POS tagging. - Learning representation
Another way is to learn a new representations that are invariant to the data sources. Domain Adversarial Neural Network (DANN) uses a domain classifier as a proxy-a-distance (PAD) to measure the distance between source and target domain. A good domain-invariant representation should be able to confuse the domain classifier whether it comes from source or target domain. Another example is to use MMD to reduce the discrepancy between representations belonging to the two domains. - Decision in the wild
Predicting performance drops on target domain where no labelled data are available is an important practical problem. Some previous work uses information theoretic measures like cross entropy, Renyi and KL divergence to predict performance drops in a new domain.
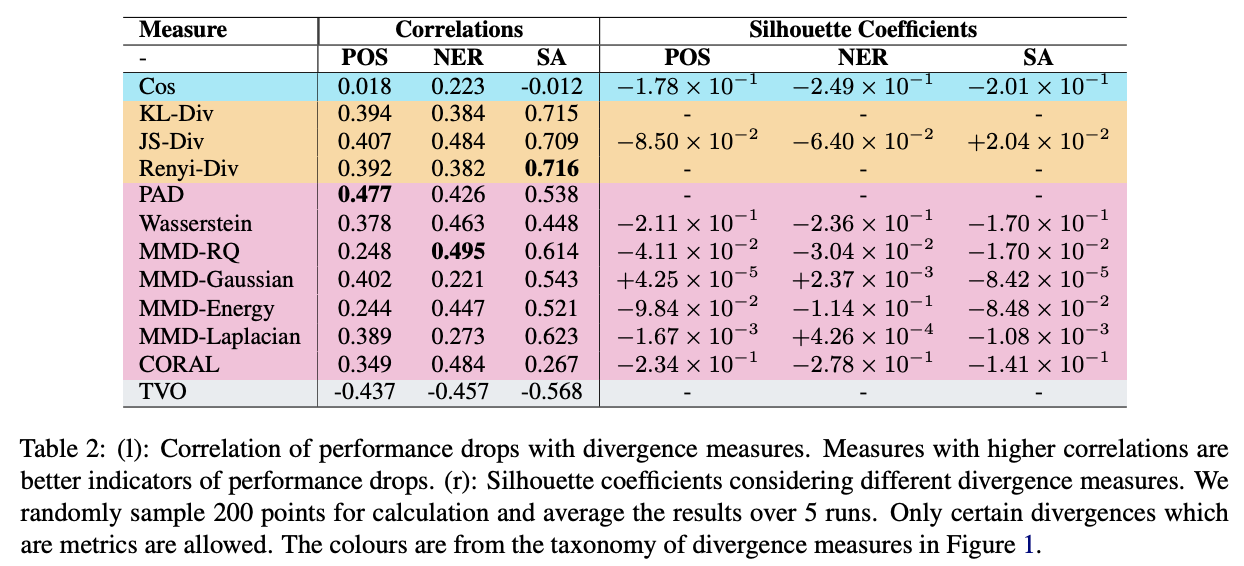
The authors also run an experiment to see the correlation between divergence measures and performance drops in target domain. More detail experiment setting and discussion can be read in the paper. Here are some recommendation from the authors based on their experiments:
- PAD is a reliable indicator of performance drop.
- JS divergence is easy to compute, and can be a strong baseline.
- Cosine similarity is not a reliable indicator of performance drop.
- One dataset is not one domain, but a cluster representations of multiple domains.
That’s all for today. Stay safe and see you next week!